
pythonを学び始めた方の中には統計ソフトとしての使い方もできるから、
という方もいるのではないでしょうか?
実際に私はその一人ですが、pythonを使った統計学のサンプルコードを置いているサイトって少ない気がするんですよね
置いてあっても用いるデータが
A = np.array([13.8, 3.8, 4.6, 10.0, 4.2, 16.1, 14.4, 4.9, 7.8, 11.4])
B = np.array([3.3, 1.1, 4.0, 4.7, 1.9, 3.1, 4.7, 5.3, 4.3, 3.0, 1.0])とかって感じになっているんですよね
これだと、excelデータやcsvデータから読み込んだ場合に、統計がかけられないんですよね
なので、実際にexcelやcsvから読み込んだデータをどのようにマンホイットニーのU検定にかけるかの説明をしていきたいと思います
pythonで統計学を学ぶ流れは以下の記事を参考にしてください
Contents
マンホイットニーのU検定
マンホイットニーのU検定は「ウィルコクソンの順位和検定」とも呼ばれている、ノンパラメトリック検定の一つです
「ウィルコクソン」とつくノンパラメトリック検定にはもう一つ、
「ウィルコクソンの符号付き順位検定」というものがあります
両者は似たような名前ですが、使用する場面が異なります
マンホイットニーのU検定では、2つのデータに対応がない場合に使用します
それに対して、ウィルコクソンの符号付き順位検定では、ノンパラメトリック検定で、2つのデータに対応がある場合に使用します

マンホイットニーのU検定とウィルコクソンの符号付き順位検定
マンホイットニーのU検定では、
帰無仮説H0:「2群の母代表値に差はない」
対立仮説H1:「2群の母代表値に差がある」
ということになります
それに対して、ウィルコクソン符号付き順位検定では、
帰無仮説H0:「母代表値に差はない」
対立仮説H1:「母代表値に差がある」
ということになります
マンホイットニーのU検定をかける手順
マンホイットニーのU検定をかける前提として、
- 独立した2群
- 正規性がない
というのが前提になります
そのため、まずは対応のあるデータかどうか?
対応のないデータである場合には、正規性の有無は?
ということを確認しなくてはいけません

EZRでマンホイットニーのU検定をかける
余談ですが、EZRでは対応のあるなしでデータの置き方が変わります
対応がない場合には以下のようになります
| Group | Sitting height |
| A | 68 |
| A | 72 |
| A | 89 |
| A | 68 |
| A | 75 |
| A | 77 |
| B | 73 |
| B | 83 |
| B | 69 |
| B | 88 |
| B | 85 |
| B | 70 |
(sitting height=座高)
それに対して、対応がある場合には以下のようになります
| Sitting height(morning) | Sitting height(evening) |
| 68 | 68 |
| 72 | 72 |
| 89 | 89 |
| 68 | 68 |
| 75 | 75 |
| 77 | 77 |
| 73 | 73 |
| 81 | 83 |
| 75 | 73 |
| 77 | 75 |
| 73 | 72 |
| 83 | 80 |
| 69 | 71 |
時間帯による座高の違いを比べた場合には上記のような記載方法になります
これ、めんどくさくないですか?
対応の有無によってデータの配置を変えるの
僕は超絶めんどくさいと思っているので、これを同じ並びのデータで同じ結果を得られるようにpythonで作ってみました
pythonでマンホイットニーのU検定をかけてみる
pythonでマンホイットニーのU検定をかける場合には、scipyのstatsを使用します
from scipy import stats
stats.mannwhitneyu(A, B, alternative='two-sided')これでマンホイットニーのU検定をかけることができます
「alternative」は両側検定か片側検定かです
デフォルトでは両側検定になっているので、指定しなくてもOKです
参考サイト>>>scipy.stats.mannwhitneyu
csvから取り込んだデータを2群に分ける
ではcsvから読み込んだデータを2群に分けていきます
import pandas as pd
import os
import csv
from scipy import stats
def MannWhitneyUtest():
type = [("all file","*")] # 読み取るファイルをcsvに絞り込む。
file_path_stastics = filedialog.askopenfilename(filetypes = type, initialdir = os.getcwd ())
stasticsdata = pd.read_csv(file_path_stastics, engine="python",index_col=None)
print(stasticsdata)
A_list=stasticsdata.iloc[:,2]
A=list(A_list)
B_list=stasticsdata.iloc[:,3]
B=list(B_list)
result=stats.mannwhitneyu(A, B, alternative='two-sided')
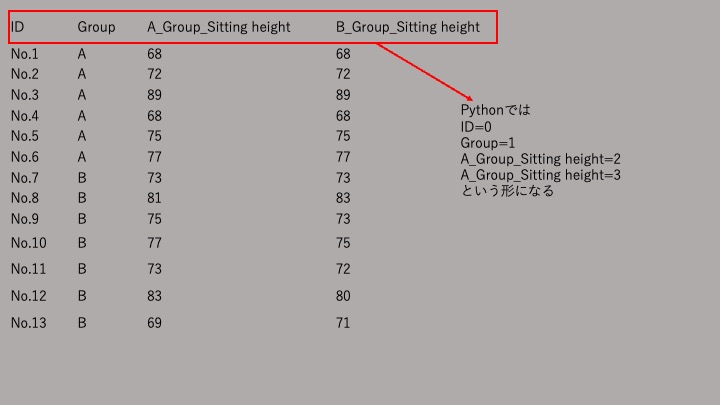
| ID | Group | A_Group_Sitting height | B_Group_Sitting height |
| No.1 | A | 68 | 68 |
| No.2 | A | 72 | 72 |
| No.3 | A | 89 | 89 |
| No.4 | A | 68 | 68 |
| No.5 | A | 75 | 75 |
| No.6 | A | 77 | 77 |
| No.7 | B | 73 | 73 |
| No.8 | B | 81 | 83 |
| No.9 | B | 75 | 73 |
| No.10 | B | 77 | 75 |
| No.11 | B | 73 | 72 |
| No.12 | B | 83 | 80 |
| No.13 | B | 69 | 71 |
上記のようなcsvデータが読み取ります
# 読み取るファイル形式を絞る(今回の場合は全てのファイル)
type = [("all file","*")]
#ファイル参照画面を開いて、ファイルを選択する
file_path_stastics = filedialog.askopenfilename(filetypes = type, initialdir = os.getcwd ())
#選択したcsvファイルを読み込み、インデックスはNone(なし)とする
stasticsdata = pd.read_csv(file_path_stastics, engine="python",index_col=None)
#stasticsdataの中身を確認する
print(stasticsdata)この状態で「stasticsdata」にcsvデータが読み込まれます
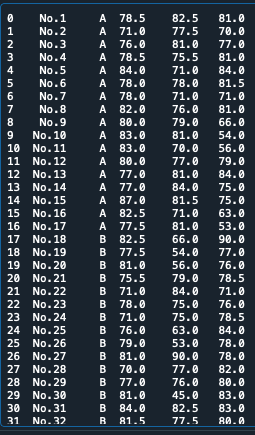
今回のcsvのデータとは異なりますが、読み込めていると、上記のように表出されるはずです
これだとA群とB群の指定がまだできていないため、統計をかけたい値をA群・B群に指定していきます
#2列目をA群として読み込む
A_list=stasticsdata.iloc[:,2]
#読み込んだ2列目をリスト形式にする
A=list(A_list)
#3列目をB群として読み込む
B_list=stasticsdata.iloc[:,3]
#読み込んだ3列目をリスト形式にする
B=list(B_list)
#マンホイットニーのU検定をかける(両側検定)
result=stats.mannwhitneyu(A, B, alternative='two-sided')
上記のコードで好きな列をA群・B群に指定することができます
pythonではcsv1列目のデータが「0」として表現されるので、0からのスタートになります
ilocを使えば列番号で指定して、取り出すことができます

| ID | Group | A_Group_Sitting height | B_Group_Sitting height |
| No.1 | A | 68 | 68 |
| No.2 | A | 72 | 72 |
| No.3 | A | 89 | 89 |
| No.4 | A | 68 | 68 |
| No.5 | A | 75 | 75 |
| No.6 | A | 77 | 77 |
| No.7 | B | 73 | 73 |
| No.8 | B | 81 | 83 |
| No.9 | B | 75 | 73 |
| No.10 | B | 77 | 75 |
| No.11 | B | 73 | 72 |
| No.12 | B | 83 | 80 |
| No.13 | B | 69 | 71 |
あとは実行すれば検定結果が表示されるはずです
私はGUIで作成しているので、検定結果をリストボックスに表示させています
listbox1.insert(tk.END,"p=%.5f" %(result.pvalue))まとめ
pythonを使えば簡単に統計をかけることができます
統計をかけること自体は簡単に行えますが、群の設定やcsvから取り込んだデータの処理などがややめんどくさいかもしれません
しかし、一度作ってしまえば、他の統計をかけるときも
stats.xxxxxx()
xのところだけを変えるのみで済むので、スムーズに作ることができると思います
さらにGUIにしてしまえば、自分だけではなく、pythonの入っていないパソコンでも使うことができます
ぜひ参考にしてみてください
私がpythonを学ぶのに参考にした書籍は以下です

スクールに通わずにpythonを学習するためには?
Python学習を進めていく上で、
「ひとまず何かしらの書籍に目を通したい」
「webで調べても全くわからない」
という状況が何度も何度でも出てくるかと思います。
そういう時に便利なのが、kindleとテラテイルです。
Kindleはご存知の通り、電子書籍です。
Kindleには多くのpython学習本が用意されており、無料で読むことができます。(たまに有料もあります)
ひとまずどういった書籍があるのか?
もしものために、書籍に目を通しておこう
という場合には、kindleの利用がおすすめです。
おすすめプログラミングスクール(無料体験あり)
![]()
WEBCAMPを徹底解説している記事はこちら

アイデミープレミアムを徹底解説している記事はこちら

テックアカデミーを徹底解説している記事はこちら









