
形態素解析とは自然言語処理の一種です
今回はpythonで形態素解析を行なっていきたいと思います
pythonで形態素解析エンジンMeCabを使用する方法についても併せて解説していきますので、参考にしてみてください
また、僕自身が収益化したサンプルコードも載せています
こんなあなたにおすすめ
pythonで形態素解析を行いたい
pythonでデータ分析の引き出しを増やしたい
pythonのMeCabを使ってみたい
独学で収益を出した方法は以下の記事から

Contents
pythonで形態素解析をやってみよう【収益化したサンプルコードあり】

まずは完成しているサンプルコードから
サンプルコードの解説は記事の後半でしていきます
import collections
import MeCab
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import seaborn as sns
sns.set(font='Hiragino Sans')
f= open('.txt', 'r', encoding='UTF-8')
text=f.read()
f.close()
tagger =MeCab.Tagger()
tagger.parse('')
node = tagger.parseToNode(text)
word_list=[]
while node:
word_type = node.feature.split(',')[0]
if word_type in ["名詞",'代名詞']:
word_list.append(node.surface)
node=node.next
word_chain=' '.join(word_list)
c=collections.Counter(word_list)
font_path='/System/Library/Fonts/ヒラギノ明朝 ProN.ttc'
words = ["もの","こと","あれ","それ","どれ","です","ます","こと"]
result = WordCloud(width=800, height=600, background_color='white',
font_path=font_path,regexp=r"[\w']+",
stopwords=words).generate(word_chain)
result.to_file("./wordcloud_sample1.png")
print(c.most_common(20))
fig = plt.subplots(figsize=(8, 10))
sns.set(font="Hiragino Maru Gothic Pro",context="talk",style="white")
sns.countplot(y=word_list,order=[i[0] for i in c.most_common(20)],palette="Blues_r")形態素解析とは?

形態素解析とは、文を単語単位に区切り、各単語の品詞を特定する解析技術のことを指しています
形態素解析(けいたいそかいせき、Morphological Analysis)とは、文法的な情報の注記の無い自然言語のテキストデータ(文)から、対象言語の文法や、辞書と呼ばれる単語の品詞等の情報にもとづき、形態素(Morpheme, おおまかにいえば、言語で意味を持つ最小単位)の列に分割し、それぞれの形態素の品詞等を判別する作業である。自然言語処理の分野における主要なテーマのひとつであり、機械翻訳やかな漢字変換など応用も多い(もちろん、かな漢字変換の場合は入力が通常の文と異なり全てひらがなであり、その先に続く文章もその時点では存在しないなどの理由で、内容は機械翻訳の場合とは異なったものになる)。
言葉だけでは分かりにくいので、実際にやってみましょう
import MeCab
mecab = MeCab.Tagger('-Ochasen')
sent ="昨日はHTMLの勉強をした"
print(mecab.parse(sent))
>>>出力結果
昨日 キノウ 昨日 名詞-副詞可能
は ハ は 助詞-係助詞
HTML HTML HTML 名詞-固有名詞-組織
の ノ の 助詞-連体化
勉強 ベンキョウ 勉強 名詞-サ変接続
を ヲ を 助詞-格助詞-一般
し シ する 動詞-自立 サ変・スル 連用形
た タ た 助動詞 特殊・タ 基本形
EOSこのように文を単語ごとに区切り、単語の品詞を特定してくれています
これが形態素解析となります
また、形態素解析は自然言語処理の分野における主要なテーマでもあります
Mecabとは?
MeCabとは、形態素解析が行えるソフトウェアのことを指します
pythonのライブラリではありませんが、MeCabとpythonは連携して使用することができます
自然言語処理
自然言語処理とは普段私たちが使用している言葉を、言葉が持つ意味を様々な方法で解析することを指します
自然言語処理は形態素解析の他にも、以下のようなものがあります
- 構文解析
- 意味解析
- 文脈解析
形態素解析の内容
サンプルコードでは単語を区切り、品詞を特定し、活用形まで出力してくれています
実際には、
- 単語への分かち書き
- 各単語の品詞の特定
- 活用形の特定
という流れで処理がされています
単語への分かち書き
単語への分かち書きというのは、文を最小単位である単語に分ける作業のことを言います
import MeCab
mecab = MeCab.Tagger('-Owakati')
sent ="昨日はHTMLの勉強をした"
print(mecab.parse(sent))
>>>出力結果
昨日 キノウ 昨日 名詞-副詞可能
は ハ は 助詞-係助詞
HTML HTML HTML 名詞-固有名詞-組織
の ノ の 助詞-連体化
勉強 ベンキョウ 勉強 名詞-サ変接続
を ヲ を 助詞-格助詞-一般
し シ する 動詞-自立 サ変・スル 連用形
た タ た 助動詞 特殊・タ 基本形
EOS今回の例で言うと、
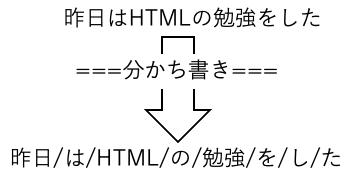
上記のようになります
各単語の品詞の特定
次に各単語の品詞の特定ですが、以下のようになります
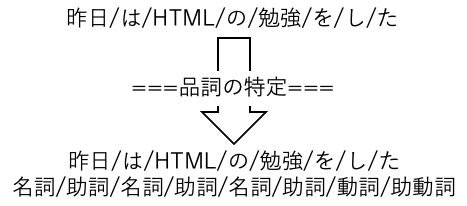
pythonを使った形態素解析では、より細かく格助詞や終助詞なども特定してくれます
これをうまく使えば、文章を抜き出してきて(作って)中学生の文法の問題を作ることも可能ですね
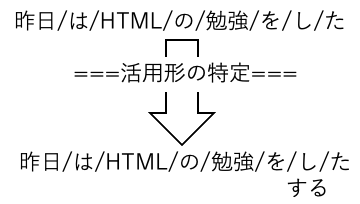
活用形の特定
最後に活用形の特定です
活用形は自立語の用言(動詞・形容詞・形容動詞)と付属語の助動詞のみになります
そもそも国語の文法として、上記4種類しか活用しないので、それ以外は表示されません
pythonで形態素解析を行う準備

ではpythonで形態素解析を行うための準備をしていきます
pythonで形態素解析を行うためには「MeCab」と言うエンジンを使用します
MeCabの環境構築
筆者はM1 Macを使用しているので、windowsユーザーの方は公式ホームページをご覧ください
流れとしては以下のようになります
- Homebrewのインストール
- MeCabと形態素解析に必要な辞書をインストール
- MeCabの動作確認
- mecab-ipadic-NEologdのインストール
Homebrewのインストール
まずはHomebrewをインストールしておきます
ターミナルを開いて以下のコマンドを実行します
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
その後、パスワードの入力を求められるので、パスワードを入力します
途中で以下の内容が表示されるので、表示されたらEnterを押します
Press RETURN to continue or any other key to abortHomebrewのインストールが終わったら、パスを追加していきます
==> Next steps:
-Add Homebrew to your PATH in /Users/ユーザ名/.zprofile:
echo 'eval "$(/opt/homebrew/bin/brew shellenv)"' >> /Users/ユーザ名/.zprofile
eval "$(/opt/homebrew/bin/brew shellenv)"
-Run 'brew help' to get started
-Further documentation:
https://docs.brew.shecho 'eval "$(/opt/homebrew/bin/brew shellenv)"' >> /Users/ユーザ名/.zprofile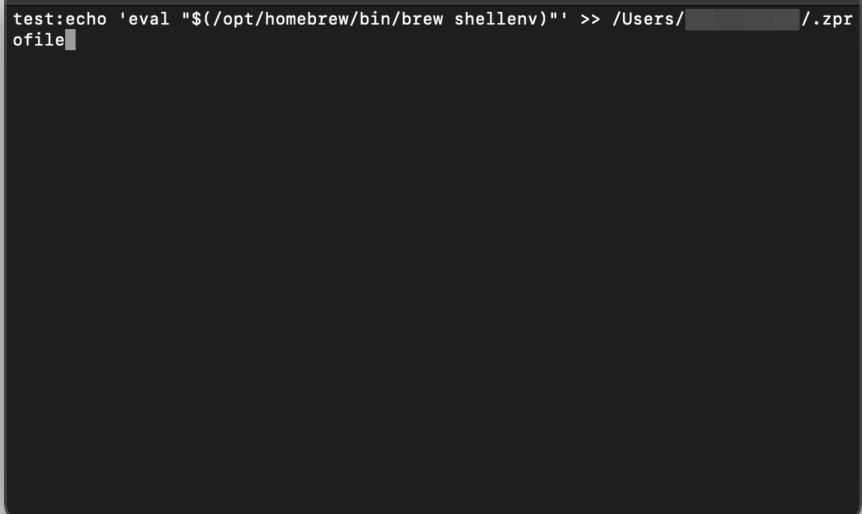
Homebrewが正常にインストールされ、パスが通っているかを確認します
brew help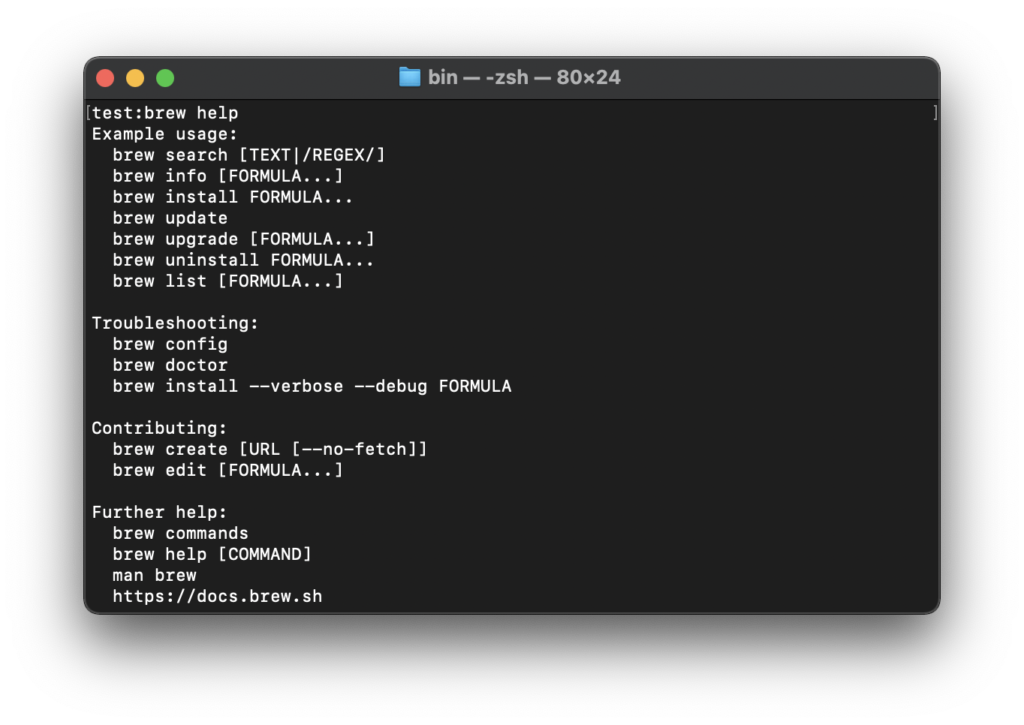
上記の画面が表示されれば、Homebrewのインストールとパスは正常に通っているのでOKです
MeCabと形態素解析に必要な辞書をインストール
Homebrewのインストールが完了したら、MeCabおよび形態素解析に必要な辞書をインストールしていきます
これもターミナル上で行なっていきます
brew install mecab
brew install mecab-ipadic
pip install mecab-python3MeCabおよび形態素解析に必要な辞書をインストールはこれで完了です
Mecabの動作確認
そのままターミナル上でMeCabの動作確認を行なっていきます
python
import MeCabMeCabをインポートしてエラーが出なければ準備完了です
pythonでMecabを使って形態素解析を行う

では実際に形態素解析を行っていきましょう
最初に示しているサンプルコードはまた違ったサンプルコードで実行していきます
MeCabの基本
MeCabでは基本的に以下の順番で出力されます
形態素の表層形, 品詞, 品詞細分類1, 品詞細分類2, 品詞細分類3, 活用型, 活用形, 原形, 読み,発音
import MeCab
tagger = MeCab.Tagger()
print(tagger.parse("昨日はHTMLの勉強をした").split())
>>>出力結果
['昨日', 'キノー', 'キノウ', '昨日', '名詞-普通名詞-副詞可能', '2,0', 'は', 'ワ', 'ハ', 'は', '助詞-係助詞', 'HTML', 'HTML', 'HTML', 'HTML', '名詞-普通名詞-一般', '0', 'の', 'ノ', 'ノ', 'の', '助詞-格助詞', '勉強', 'ベンキョー', 'ベンキョウ', '勉強', '名詞-普通名詞-サ変可能', '0', 'を', 'オ', 'ヲ', 'を', '助詞-格助詞', 'し', 'シ', 'スル', '為る', '動詞-非自立可能', 'サ行変格', '連用形-一般', '0', 'た', 'タ', 'タ', 'た', '助動詞', '助動詞-タ', '終止形-一般', 'EOS']splitしない場合
splitをしない場合のMecabの出力結果はこちら
import MeCab
mecab = MeCab.Tagger()
sent ="昨日はHTMLの勉強をした"
print(mecab.parse(sent))
>>>出力結果
昨日 キノウ 昨日 名詞-副詞可能
は ハ は 助詞-係助詞
HTML HTML HTML 名詞-固有名詞-組織
の ノ の 助詞-連体化
勉強 ベンキョウ 勉強 名詞-サ変接続
を ヲ を 助詞-格助詞-一般
し シ する 動詞-自立 サ変・スル 連用形
た タ た 助動詞 特殊・タ 基本形
EOS分かち書き
次に形態素解析の基本である、分かち書きを進めていきます
import MeCab
tagger = MeCab.Tagger("-Owakati")
print(tagger.parse("昨日はHTMLの勉強をした").split())
>>>出力結果
['昨日', 'は', 'HTML', 'の', '勉強', 'を', 'し', 'た']MeCab.Tagger()
MeCab.Tagger()で形態素解析を行うための辞書を指定します
このTaggerは「タグ付けする」という意味になります
MeCabにTaggerでタグ付けをするということです
MeCab::Tagger のコンストラクタの引数は, 基本的に mecab の実行形式に与えるパラメータと同一で, それらを文字列として与えます.
MeCab公式HPより
今回のサンプルコードは「-Owakati」を指定していますが、それ以外にも、
- MeCab.Tagger(“-Ochasen”):ChaSen互換形式
- MeCab.Tagger(“-Oyomi”):読みのみを出力
- MeCab.Tagger(“-Odump”):単語の全情報
- MeCab.Tagger(“-Osimple”):シンプルな形態素解析
などがあります
import MeCab
mecab = MeCab.Tagger('-Ochasen')
sent ="昨日はHTMLの勉強をした"
print(mecab.parse(sent))
>>>出力結果
昨日 キノウ 昨日 名詞-副詞可能
は ハ は 助詞-係助詞
HTML HTML HTML 名詞-固有名詞-組織
の ノ の 助詞-連体化
勉強 ベンキョウ 勉強 名詞-サ変接続
を ヲ を 助詞-格助詞-一般
し シ する 動詞-自立 サ変・スル 連用形
た タ た 助動詞 特殊・タ 基本形
EOSimport MeCab
mecab = MeCab.Tagger('-Oyomi')
sent ="昨日はHTMLの勉強をした"
print(mecab.parse(sent))
>>>出力結果
キノウハHTMLノベンキョウヲシタimport MeCab
mecab = MeCab.Tagger('-Odump')
sent ="昨日はHTMLの勉強をした"
print(mecab.parse(sent))
>>>出力結果
0 BOS BOS/EOS,*,*,*,*,*,*,*,* 0 0 0 0 0 0 2 1 0.000000 0.000000 0.000000 0
2 昨日 名詞,副詞可能,*,*,*,*,昨日,キノウ,キノー 0 6 1314 1314 67 2 0 1 0.000000 0.000000 0.000000 4626
14 は 助詞,係助詞,*,*,*,*,は,ハ,ワ 6 9 261 261 16 6 0 1 0.000000 0.000000 0.000000 5501
19 HTML 名詞,固有名詞,組織,*,*,*,* 9 13 1292 1292 45 5 1 1 0.000000 0.000000 0.000000 18682
24 の 助詞,連体化,*,*,*,*,の,ノ,ノ 13 16 368 368 24 6 0 1 0.000000 0.000000 0.000000 19304
30 勉強 名詞,サ変接続,*,*,*,*,勉強,ベンキョウ,ベンキョー 16 22 1283 1283 36 2 0 1 0.000000 0.000000 0.000000 21841
35 を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ 22 25 156 156 13 6 0 1 0.000000 0.000000 0.000000 21392
41 し 動詞,自立,*,*,サ変・スル,連用形,する,シ,シ 25 28 610 610 31 6 0 1 0.000000 0.000000 0.000000 24165
44 た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ 28 31 435 435 25 6 0 1 0.000000 0.000000 0.000000 21709
47 EOS BOS/EOS,*,*,*,*,*,*,*,* 31 31 0 0 0 0 3 1 0.000000 0.000000 0.000000 20599import MeCab
mecab = MeCab.Tagger('-Osimple')
sent ="昨日はHTMLの勉強をした"
print(mecab.parse(sent))
>>>出力結果
昨日 名詞-副詞可能
は 助詞-係助詞
の 助詞-連体化
勉強 名詞-サ変接続
を 助詞-格助詞-一般
し 動詞-自立
た 助動詞
EOSmecab.parse()
mecab.parseでは、指定した辞書を使用して、指定した文字列やテキストファイルの形態素解析を実施していきます
sentを指定しなくても、文字列を直接入力すれば、形態素解析を行うことができます
しかし、形態素解析を行う場合の多くはテキストファイルなどから読み込んで実行をすると思いますので、指定する方が便利だと思います
import MeCab
mecab = MeCab.Tagger('-Osimple')
#sent ="昨日はHTMLの勉強をした"
print(mecab.parse("昨日はHTMLの勉強をした"))
>>>出力結果
昨日 名詞-副詞可能
は 助詞-係助詞
の 助詞-連体化
勉強 名詞-サ変接続
を 助詞-格助詞-一般
し 動詞-自立
た 助動詞
EOSmecab.parseToNode()
前回の記事のサンプルコードでは、「mecab.parseToNode()」を使用しました
これを使用することで、最初のnodeを取得し、node.nextとすることで、次のnodeに移ります
surfaceには単語が、featureには特徴(品詞の種類や活用形など)が含まれます
import collections
import MeCab
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import seaborn as sns
sns.set(font='Hiragino Sans')
f= open('.txt', 'r', encoding='UTF-8')
text=f.read()
f.close()
tagger =MeCab.Tagger()
tagger.parse('')
node = tagger.parseToNode(text)
word_list=[]
while node:
word_type = node.feature.split(',')[0]
if word_type in ["名詞",'代名詞']:
word_list.append(node.surface)
node=node.next
word_chain=' '.join(word_list)形態素解析に出てきた品詞の数を数える
形態素解析を実施した後に、どの品詞がどれくらいの数出てきているのかを知りたい時があります
そういう時は「collections.Counter」を使用することで数を数えることができます
import collections
・・・省略・・・
・・・省略・・・
・・・省略・・・
・・・省略・・・
word_list=[]
while node:
word_type = node.feature.split(',')[0]
if word_type in ["名詞",'代名詞']:
word_list.append(node.surface)
node=node.next
word_chain=' '.join(word_list)
#word_listの中身を数える
c=collections.Counter(word_list)形態素解析のサンプルコードを解説
では最後に以下のサンプルコードの解説をしていきます
今回は形態素解析を行いつつ、wordcloudを実行していきます
こんな感じの画像を作成していきます

使用するテキストは首相の会見内容を行っていきます
こちらのページの内容をコピペしてテキストファイルとして保存しておきましょう
import collections
import MeCab
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import seaborn as sns
sns.set(font='Hiragino Sans')
#textファイルの読み込み
f= open('.txt', 'r', encoding='UTF-8')
text=f.read()
f.close()
#読み込んだtextファイルで形態素解析を行う
tagger =MeCab.Tagger()
tagger.parse('')
node = tagger.parseToNode(text)
#取り出す品詞を決めている.今回は名詞と代名詞
word_list=[]
while node:
word_type = node.feature.split(',')[0]
if word_type in ["名詞",'代名詞']:
word_list.append(node.surface)
node=node.next
word_chain=' '.join(word_list)
c=collections.Counter(word_list)
#フォントパスの指定
font_path='/System/Library/Fonts/ヒラギノ明朝 ProN.ttc'
#wordcloud上から除外するワードの設定
words = ["もの","こと","あれ","それ","どれ","です","ます","こと"]
#wordcloudを実行する
#regexp=r"[\w']+"で1文字のものも取り出す
#result.to_fileでpngファイルとして出力
#printでよく使われている単語top20を出力
result = WordCloud(width=800, height=600, background_color='white',
font_path=font_path,regexp=r"[\w']+",
stopwords=words).generate(word_chain)
result.to_file("./wordcloud_sample1.png")
print(c.most_common(20))
#形態素解析の結果と合わせてグラフ化する
fig = plt.subplots(figsize=(8, 10))
sns.set(font="Hiragino Maru Gothic Pro",context="talk",style="white")
sns.countplot(y=word_list,order=[i[0] for i in c.most_common(20)],palette="Blues_r")
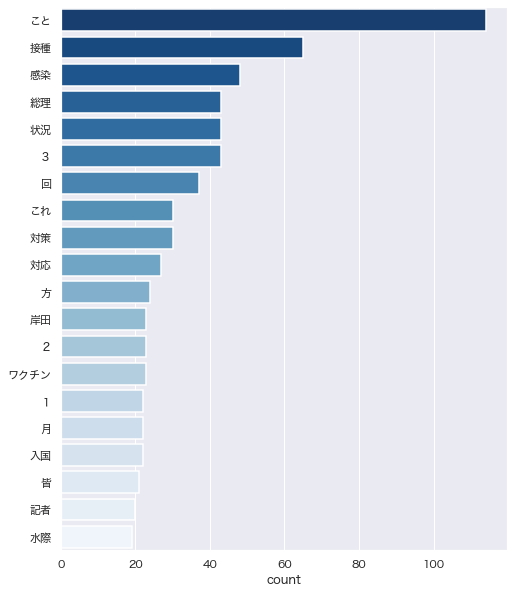
>>>出力結果
[('こと', 114), ('接種', 65), ('感染', 48),
('総理', 43), ('状況', 43), ('3', 43), ('回', 37),
('これ', 30), ('対策', 30), ('対応', 27), ('方', 24),
('岸田', 23), ('2', 23), ('ワクチン', 23), ('1', 22),
('月', 22), ('入国', 22), ('皆', 21), ('記者', 20), ('水際', 19)]形態素解析のtop20をグラフ化した結果
pythonで形態素解析をやってみよう【収益化したサンプルコードあり】のまとめ
- pythonで形態素解析をうまく使えば収益化可能
- 形態素解析を行ったら作図も可能
- 文字起こし→形態素解析・wordcloudのセットだとよりgood
- MeCabは形態素解析用のソフトウェア
- MeCabとpythonは連携して使うことができる
- 指定の品詞のみや品詞の数をカウントすることができる








