
t検定などの統計手法をかける場合には、まずそのデータが正規分布しているかを調べなくてはいけません
正規性を確認する方法の一つに、ヒストグラムを書いて目視で確認する、という方法がありますが、これだけでは正確ではありません
そこで、「Q-Qプロット」や「シャピロウィルク検定」「コルモゴロフスミルノフ検定」などを使用して、正規性を確認していきます
実際に統計をかける場合には、csvやexcelデータなどを読み込んで、統計にかけることが多いと思います
そこで今回は、pythonを使ってcsvから取り込んだデータで正規性の検定を行う方法について、解説していきたいと思います
pythonで統計学を学ぶ流れは以下の記事を参考にしてください
Contents
正規性の検定とは
正規性の検定とは、データの母集団が正規分布に従っているかどうかを調べる検定です
コルモゴロフスミルノフ検定やリリフォース検定、シャピロウィルク検定などがあります
正規性がある場合にはパラメトリック検定を用い、
正規性がない場合にはノンパラメトリック検定を用いる必要があります
正規性の検定の仮説は以下のようになっています
- 帰無仮説H0:「データの母集団は正規分布に従っている」
- 対立仮説H1:「データの母集団は正規分布に従っていない」
検定統計量が定めた有意水準以下の場合には、帰無仮説が棄却されることになります

pythonで正規性の検定を行う
pythonで正規性の検定を行う場合には、scipy.statsを使用します
コルモゴロフスミルノフ検定はデータ数が多い場合に使用します
データ数の目安は1000以上とされています
今回はe-statで無料配布されているデータセットを用いて正規性の検定をかけていきたいと思います
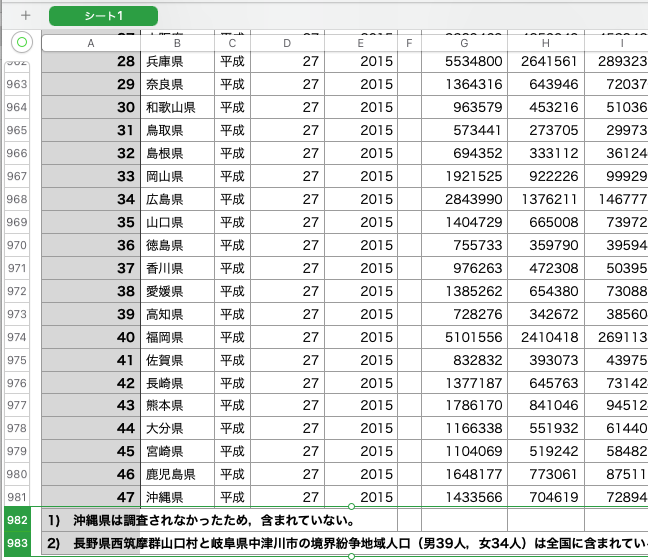
下から2行は不要なので、削除して使用をします
pythonでシャピロウィルク検定をかける
pythonでシャピロウィルク検定をかける場合には、以下のように記載をします
scipy.stats.shapiro(x)xには該当するデータを入力すればOKです
私のシャピロウィルク検定のサンプルコードはこちら
def btn_click1():
filename = filedialog.askopenfilename(
filetypes=[('csv files', '*.csv')], initialdir=os.getcwd())
if not filename == '':
with open(filename, 'r') as f:
reader = csv.reader(f)
headerList = reader.__next__()
listBoxData = {}
listbox.delete(0, tk.END)
listbox1.delete(0, tk.END)
for i in range(0,len(headerList)):
listBoxData[i]={}
listBoxData[i]['name']=headerList[i]
listBoxData[i]['list']=[]
listbox.insert(tk.END,headerList[i])
for rowList in reader:
for j in range(0,len(rowList)):
listBoxData[j]['list'].append(rowList[j])
def shapiro(event):
selectIdx=listbox.curselection()
if len(selectIdx)>0:
listbox1.delete(0,tk.END)
a=stats.shapiro(listBoxData[selectIdx[0]]['list'])
listbox1.insert(tk.END,"Statistics=%.3f,p=%.3f" %(a))
listbox.bind("<<ListboxSelect>>",shapiro)私が作成しているものでは、取り込んだcsvデータの項目に値を対応させて、それをクリックするだけで、シャピロウィルク検定の結果が表示されるようにしています
上記の方法は煩雑なので、csvから取り込んだ指定のデータを正規性の検定にかけたいと思います
csvから取り込んだ指定のデータをシャピロウィルク検定にかける
import pandas as pd
import os
import csv
from scipy import stats
def shapirotest():
type = [("all file","*")] # 読み取るファイルをcsvに絞り込む。
file_path_stastics = filedialog.askopenfilename(filetypes = type, initialdir = os.getcwd ())
stasticsdata = pd.read_csv(file_path_stastics, engine="python",index_col=None)
print(stasticsdata)
A_list=stasticsdata.iloc[:,2]
A=list(A_list)
B_list=stasticsdata.iloc[:,3]
B=list(B_list)
result=stats.shapiro(A)
result=stats.shapiro(B)上記コードで2列目と3列目のデータをシャピロウィルク検定にかけることができます
A_list=stasticsdata.iloc[:,2]上記の[:2]の部分を3,4,5…と変えていけば、4列目,5列目…
をシャピロウィルク検定にかけることが可能です
pythonでコルモゴロフスミルノフ検定をかける
pythonでコルモゴロフスミルノフ検定をかける場合には、以下のように記載をします
scipy.stats.kstest(rvs, cdf, args=(), N=20, alternative='two-sided', mode='auto')実際にはrvsの部分だけでいけるはずです
サンプルコードは以下になります
import pandas as pd
import os
import csv
from scipy import stats
def kstest():
type = [("all file","*")] # 読み取るファイルをcsvに絞り込む。
file_path_stastics = filedialog.askopenfilename(filetypes = type, initialdir = os.getcwd ())
stasticsdata = pd.read_csv(file_path_stastics, engine="python",index_col=None)
print(stasticsdata)
A_list=stasticsdata.iloc[:,2]
A=list(A_list)
B_list=stasticsdata.iloc[:,3]
B=list(B_list)
result=stats.kstest(A)
result=stats.kstest(B)シャピロウィルク検定とほぼ同じです
stats.shapiroになるか、stats.kstestになるかの違いになります
コルモゴロフスミルノフ検定ではデータ数が少ないと正しいp値が返ってこないため、データ数が少ないばあいには、シャピロウィルク検定をかけるようにしましょう
Q-Qプロットで正規性の確認を行う
最後にQ-Qプロットで正規性を確認する方法を解説していきます
scipy.stats.probplot(x, sparams=(), dist='norm', fit=True, plot=None, rvalue=False)コードは上記のようになります
私が作成したサンプルコードは以下
import pandas as pd
import os
import csv
from scipy import stats
def qq():
type = [("all file","*")] # 読み取るファイルをcsvに絞り込む。
file_path_stastics = filedialog.askopenfilename(filetypes = type, initialdir = os.getcwd ())
stasticsdata = pd.read_csv(file_path_stastics, engine="python",index_col=None)
A_list=stasticsdata.iloc[:,2]
A=list(A_list)
B_list=stasticsdata.iloc[:,3]
B=list(B_list)
stats.probplot(A, dist="norm", plot=plt)
stats.probplot(B, dist="norm", plot=plt)
plt.legend(['A','', 'B',''])
plt.show()これを実行すると、このようなQ-Qプロットが作成されます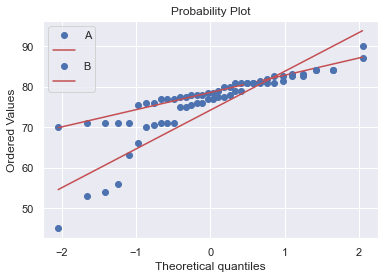
Q-Qプロットでは、正規性に従っている場合、点が直線上に並びます
今回の場合は、ちょっと悩みますが、正規分布に従っていると判断して良さそうです
Q-Qプロットだけでは判断ができない時には、シャピロウィルク検定の結果も加味して考える必要があります
まとめ
今回は正規性の検定について解説をしました
pythonを使えば簡単に統計をかけることができます
統計をかけること自体は簡単に行えますが、群の設定やcsvから取り込んだデータの処理などがややめんどくさいかもしれません
しかし、一度作ってしまえば、他の統計をかけるときも
stats.xxxxxx()
xのところだけを変えるのみで済むので、スムーズに作ることができると思います
さらにGUIにしてしまえば、自分だけではなく、pythonの入っていないパソコンでも使うことができます
ぜひ参考にしてみてください
私がpythonを学ぶのに参考にした書籍は以下です

スクールに通わずにpythonを学習するためには?
Python学習を進めていく上で、
「ひとまず何かしらの書籍に目を通したい」「webで調べても全くわからない」という状況が何度も何度でも出てくるかと思います。
そういう時に便利なのが、kindleとテラテイルです。
Kindleはご存知の通り、電子書籍です。
Kindleには多くのpython学習本が用意されており、無料で読むことができます。(たまに有料もあります)
ひとまずどういった書籍があるのか?もしものために、書籍に目を通しておこう
という場合には、kindleの利用がおすすめです。








