
BeautifulSoupはWebサイトを構成しているHTMLやXMLファイルからデータを取得し、解析するためのPython Webスクレイピングライブラリです
Web上に公開されているほとんどはHTMLやXMLが使われており、情報を取得し解析する際には、BeautifulSoupは重宝します
これまで手動で行なっていた情報収集や解析も、PythonのBeautifulSoupを活用することで自動化することができます
本記事では、BeautifulSoupを使ったスクレイピング方法について、具体例を交えて解説していきます。
実際に自動化したものをnoteに記載しているので、BeautifulSoupを応用して活用してみたい方は、そちらも参考にしてください
多すぎるキャンペーンを監視してキャンペーンが開始したらメールで通知するプログラム
PythonでスクレイピングするWebサイト(Web Scraper)を作ったよ
筆者について
2021年から本格的にPython学習を始め、今ではPythonによる収益化に成功しフリーランスエンジニアに
大学院時代には、R言語とPythonを使って統計処理を行っていたため、Pythonを使ったデータサイエンスの知識が豊富
医療データを機械学習を用いて解析したり、学会発表も行なっている
Contents
Pythonで使えるBeautifulSoupとその他のスクレイピングライブラリ
まずはBeautifulSoupを使える状態にする必要があります

スクレイピングは大まかに3つの流れで行われます
- 情報の取得
- データの抽出
- データの保存・出力
Webスクレイピングの流れ
まずは必要としている情報を取得する必要があります
HTMLには必要な情報以外にもタグと呼ばれるものが含まれています
情報を取得しただけではタグも含まれているので、データの抽出でタグ以外の情報を抽出します
例えば、次のような情報を取得した場合、タグ以外のものにする必要があります
<p>今日はとてもいい天気でした。明日もきっと晴れるでしょう</p>
<p></p>の部分がタグと呼ばれるものであり、必要としている情報はその間の「今日はとてもいい天気でした。明日もきっと晴れるでしょう」だけになります。
この状態にするまでが第2ステップです
最後に、取得した情報を保存・出力します
情報を取得するということは、何かしらに活用するためだと思います
そのため、csvやexcel形式に保存して、見返せるようにする必要があります
Webスクレイピングに使われるライブラリ
Pythonでスクレイピングを行う場合、BeautifulSoup以外にのライブラリも使われます
- Requests
- Selenium
どちらもPythonでスクレイピングを行う場合には、よく使用します
特にSeleniumを使うことで、自動でWeb操作をすることができます
BeautifulSoup、Requests、Seleniumそれぞれをどのように使うかは、次のとおりです
| ライブラリ | 情報の取得 | データの抽出 | データの保存・出力 |
| BeautifulSoup | ○ | ||
| Requests | ○ | ||
| Selenium | ○ | ○ |
Requests
Requestsでは、情報の取得を行う際に頻繁に用いられています
Requestsを使うことで、Pythonでスクレイピングを行う際に必要な情報を自動で取得することができます
Requestsで情報を取得した後、BeautifulSoupで必要な情報に抽出します
Selenium
Seleniumは情報を渡しておくと、自動ログインを行うことができたり、JacaScriptが使われているWebサイトから情報を取得することができます
また、Seleniumは情報の取得のみではなく、情報の抽出も行うことができますが、処理速度が遅いのがデメリットです
しかし、ログイン操作などを自動で行うことができるので、Cron設定をして、毎日行なっていることを自動化することが可能
Webスクレイピングを行う際には、
情報の取得・抽出だけを行う場合には、RequestsとBeautifulSoup
自動ログインなどルーティンで行う処理については、Seleniumを使う、といった使い分けが大切になります
BeautifulSoup,Requests,Seleniumの全て効率よく学びたい方は、Pythonによるビジネスに役立つWebスクレイピングがおすすめです
HTMLの基本から、実際のデータ取得まで一貫して学ぶことが出来ます
PythonでBeautifulSoupを使う準備
PythonでBeautifulSoupを使うためには、インストールを行う必要がありますが、詳細は以下の記事に記載していますので、ここでは簡単に紹介していきます
ライブラリのインストール
PythonでWebスクレイピングを行うのであれば、まずはライブラリのインストールが必要です
今回はBeautifulSoupを使った内容がメインですが、requestsを使う場面もあるので、両方ともインストールします
pip環境であれば、以下です
pip install beautifulsoup4
pip install requestsconda環境はこちらです
conda install beautifulsoup4
conda install requestsこれでbeautifulsoupとrequestsにインストールは終了です
コーディングを行っていくときは、インポートする必要があるので、冒頭に以下のコードを記載します
import requests
from bs4 import BeautifulSoupBeautifulSoupを使ったWebスクレイピング
ここからは実際にPythonでBeautifulSoupを使ってWebスクレイピングを行っていきます
今回は私が開発したAI株価予測サービスを使って実装・解説をしていきたいと思います
以下のコードではpタグを指定しているので、画像内赤枠の部分を抽出します
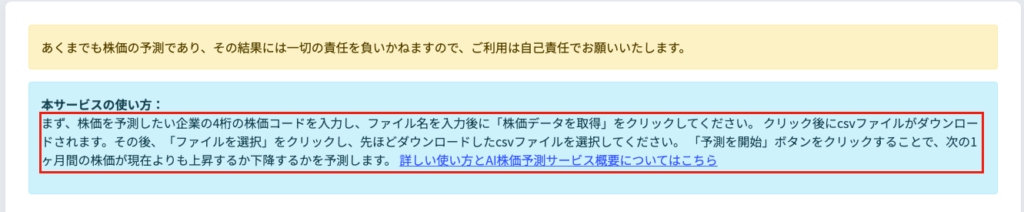
import requests
from bs4 import BeautifulSoup
# URLを指定
url = 'https://aistock.tech/'
# ページのコンテンツを取得
response = requests.get(url)
# BeautifulSoupオブジェクトを作成
soup = BeautifulSoup(response.content, 'html.parser')
#pタグをすべて見つける
p_tags = soup.find_all('p')
#pタグのテキストを表示
for p in p_tags:
print(p.get_text())
requetstを使って情報の抽出
Pythonを使ってWebスクレイピングを行う場合、まずはrequestsを使って情報を抽出します
import requests
from bs4 import BeautifulSoup
# URLを指定
url = 'https://aistock.tech/'
# ページのコンテンツを取得
response = requests.get(url)
print(response.text)
>>>出力結果
<body>
<nav class="navbar navbar-expand-lg navbar-dark bg-dark">
<div class="container-fluid">
<a class="navbar-brand" href="/">AI株価予測サービス</a>
<button class="navbar-toggler" type="button" data-bs-toggle="collapse" data-bs-target="#navbarNav"
aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation">
<span class="navbar-toggler-icon"></span>
</button>
<div class="collapse navbar-collapse" id="navbarNav">
<ul class="navbar-nav ml-auto">
<li class="nav-item">
<a class="nav-link" href="/recommended_books">Python学習におすすめの書籍</a>
</li>
<li class="nav-item">
<a class="nav-link" href="/how_to_use">使い方</a>
</li>
<li class="nav-item">
・・・一部割愛していますが、以下のコードでは指定したWebサイトのHTML、XMLの情報を全て抽出してくれます
AI株価予測サービスの1ページの情報量はそこまで多くないので、指定した文字列などを人力で探すことも可能ですが、情報量の多いWebサイトではそうはいきません
# ページのコンテンツを取得
response = requests.get(url)
print(response.text)BeautifulSoupの基本的な使い方
先ほどrequestsで抽出した情報から、必要な情報だけ抽出できるようにしましょう
requestsで取得した情報は、BeautifulSoupを使って解析していきます
BeautifulSoupの基本的な使い方は以下です
BeautifulSoup(解析対象のHTML/XML, 利用するパーサー)1つ目の引数には、解析を行うHTMLやXMLを指定し、2つ目の引数には、解析に利用するパーサーを指定します
パーサーというのは、解析器を指しており、それぞれ以下の特徴があります
| パーサー | 引数での指定方法 | 特徴 |
| Python’s html.parser | “html.parser” | 追加ライブラリ不要 |
| lxml’s HTML parser | “lxml” | 高速処理が可能 |
| lxml’s XML parser | “xml” | XMLに対応し、高速処理が可能 |
| html5lib | “html5lib” | 正しくHTML5を処理可 |
html5libの「正しくHTML5を処理可」というのは、HTMLが壊れていても正確に解析をすることができるという意味です。
また、パーサーによっては追加でインストールが必要になりますが、今回使用するPython’s html.parserは追加インストール不要です
Python’s html.parser以外を使用する場合には、以下のインストールを行いましょう
pip install lxml
pip install html5lib
サンプルコードに話を戻します
BeautifulSoupを使う部分はここでした
soup = BeautifulSoup(response.content, 'html.parser')第一引数には解析対象となるHTML、第二引数にはパーサーを指定します
ここで、第一引数の属性は一般的に「text」を使用しますが、今回は解説の意味も含めて「content」にしています
ここまでではまだrequestsで情報を取得したときと大差ありません
次に必要な情報を取得していきましょう
contentとtextの違い
「.(ドット)」より以遠にある英語を属性と呼びます
contentとtext属性の違いは次の通りです
| 特徴 | .content | .text |
| データの形式 | バイト形式 (bytes) | 文字列形式 (str) |
| 主な使用用途 | バイナリデータ(画像、ファイルなど)、エンコーディングが不明なテキストデータ | テキストベースのデータ(HTML、XML、JSONなど) |
| エンコーディング | 手動で指定する必要がある場合がある | 自動的に推測され、デコードされる |
| 一般的な使用例 | バイナリデータの取得や、特定のエンコーディングが必要な場合 | 通常のHTMLやXMLのスクレイピング |
.contentはバイト形式でデータを扱う場合やエンコーディングが特定できない場合に適しており、.text は一般的なテキストデータのスクレイピングに適しています
必要な情報の取得
ここまででBeautifulSoupを使っていますが、まだ必要な情報を取得できていません
確認したい方は以下のコードを実行しましょう。
import requests
from bs4 import BeautifulSoup
# URLを指定
url = 'https://aistock.tech/'
# ページのコンテンツを取得
response = requests.get(url)
# BeautifulSoupオブジェクトを作成
soup = BeautifulSoup(response.content, 'html.parser')
print(soup)必要な情報を取得するためには、次の3つの方法からどれかを使用します
- selectメソッド:selectメソッドを使った、CSSセレクタで該当する箇所を指定
- find、find_allメソッド:findメソッドを使い、HTMLタグの該当する箇所を検索
- 階層移動:HTMLの階層を移動して、HTMLタグの該当する場所を検索
BeautifulSoup,Requests,Seleniumの全て効率よく学びたい方は、Pythonによるビジネスに役立つWebスクレイピングがおすすめです
HTMLの基本から、実際のデータ取得まで一貫して学ぶことが出来ます
BeautifulSoupのselectメソッドの使い方
まずはselectメソッドを使った方法で情報を抽出していきます
selectメソッドを使う場合には、WebサイトからCSSセレクタを取り出す必要があります
CSSセレクタとは、HTMLから必要とする情報を選択するために使用しますが、Google Chromeを使用することで簡単に取り出すことが出来ます
Google Chromeがまだ使えない方は、インストールしておきましょう
Selectメソッドを使ったスクレイピング方法
Google Chromeが使えるようになったら、AI株価予測サービスのページをChromeで開きます。
AI株価予測サービスのメインページにある本文にマウスを合わせ、右クリック
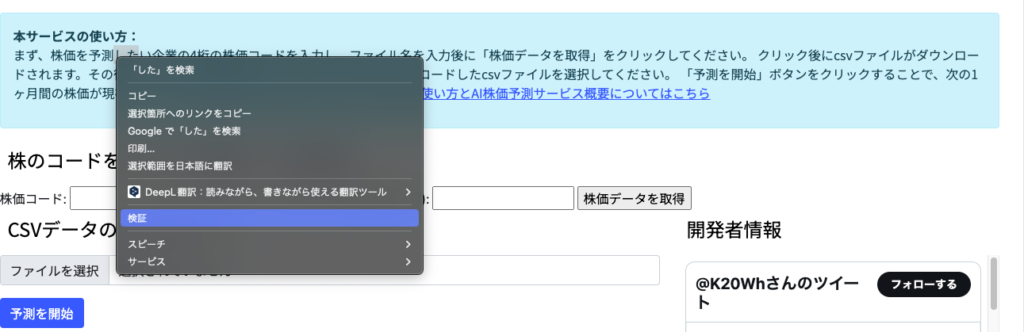
これにより、ポップアップメニューが出現します。その中から「検証」オプションを選びます。
これを選ぶと、画面の右側に新しいウィンドウが開き、HTMLコードが表示されます。
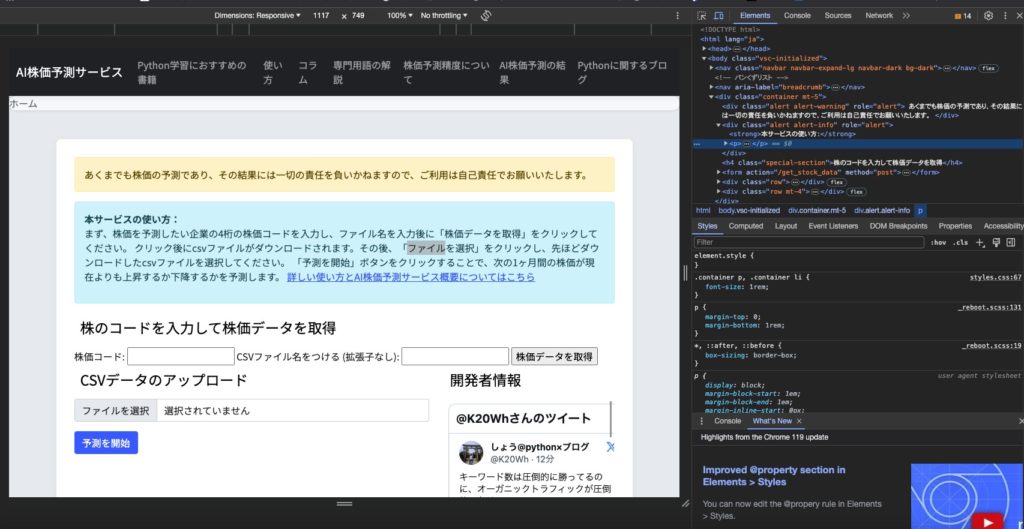
AI株価予測サービスのページの本文部分にマウスカーソルを合わせて、もう一度右クリックして検証をクリックします。
そうすると、指定した部分が網掛けになります
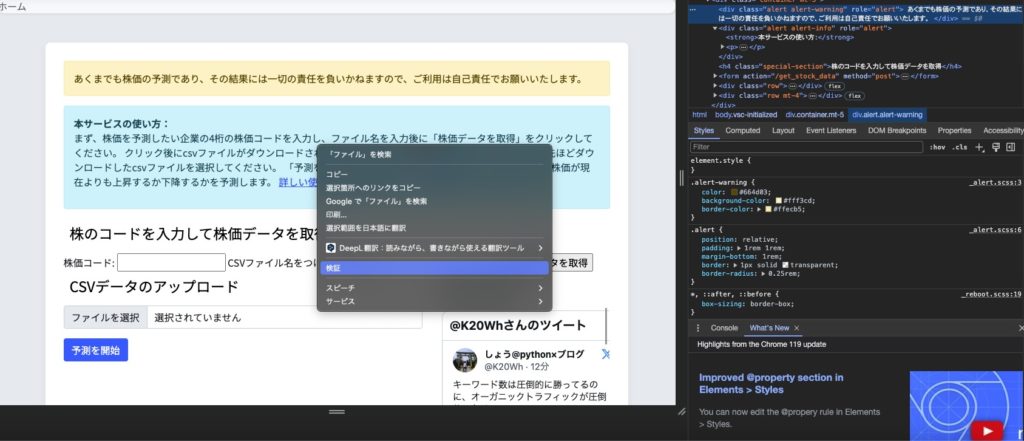
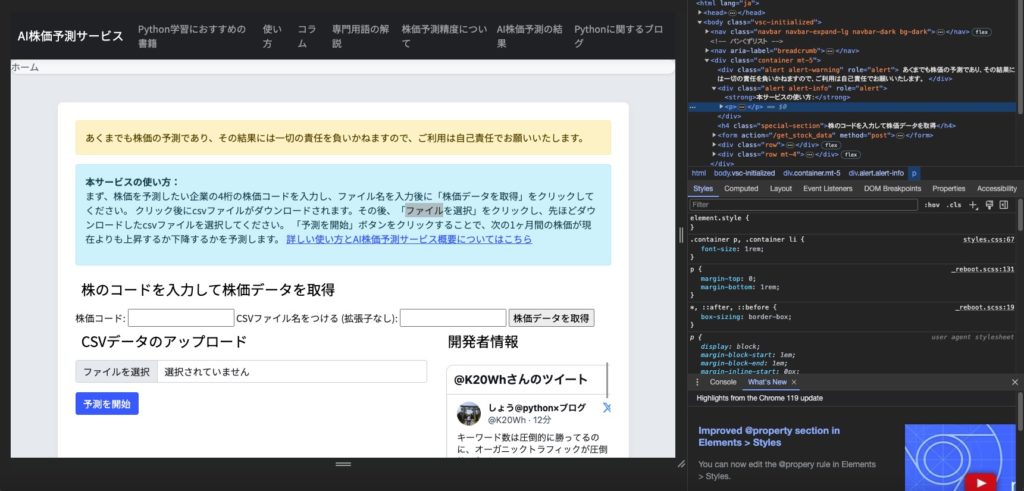 網掛けになっているタブのところでもう一度右クリックをすると、再びメニューが表示されるので、そこから「Copy」に続いて「Copy selector」を選択します。
網掛けになっているタブのところでもう一度右クリックをすると、再びメニューが表示されるので、そこから「Copy」に続いて「Copy selector」を選択します。
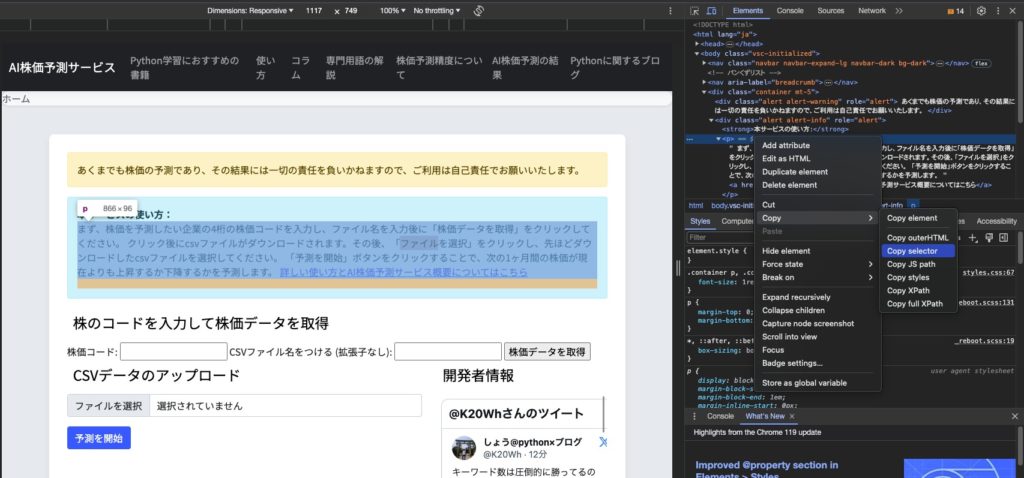 Google ChromeでコピーしたCSSセレクタは、メモ帳などのテキストエディタに貼り付けることができます。
Google ChromeでコピーしたCSSセレクタは、メモ帳などのテキストエディタに貼り付けることができます。
Selectメソッドを使ったスクレイピングの解説
今回コピーした結果は以下のようになっているはずです
body > div > div.alert.alert-info > pそうすると、AI株価予測サービスのページを特定するCSSセレクタが表示されます。これは、AI株価予測サービスのページに対応する部分の識別子となります。
取得したCSSセレクタを使用して、Beautiful Soupの soup.select() メソッドに渡すことができます。
elems=soup.select('body > div > div.alert.alert-info > p')このメソッドは、指定されたセレクタに一致するHTML要素を検索し、それらのリストを返します。
この戻り値を、変数elemsに格納します。
これにより、elemsには指定したCSSセレクタにマッチするすべての要素が含まれることになります。
ここまでの手順は、Webサイトから特定の情報を取得するための過程です。
このプロセスを完了させるために、取得した情報を表示してみることが良いでしょう。
具体的には、elemsという変数に格納された要素のリストの中から最初の要素を表示します。
Pythonでこれを行うには、次のようなコードを記述します
if elems:
print(elems[0])
else:
print("No elements found")このコードは、elemsが空でない場合、その最初の要素を出力します。
もしelemsが空の場合、つまり指定されたセレクタに一致する要素がウェブページ上に存在しない場合は、「No elements found」というメッセージを出力します。
これにより、取得した情報を確認し、プロセスが正しく機能しているかを検証することができます。
>>>出力結果
<p>
まず、株価を予測したい企業の4桁の株価コードを入力し、ファイル名を入力後に「株価データを取得」をクリックしてください。
クリック後にcsvファイルがダウンロードされます。その後、「ファイルを選択」をクリックし、先ほどダウンロードしたcsvファイルを選択してください。
「予測を開始」ボタンをクリックすることで、次の1ヶ月間の株価が現在よりも上昇するか下降するかを予測します。
<a href="/how_to_use">詳しい使い方とAI株価予測サービス概要についてはこちら</a>
</p>取得したAI株価予測サービスのページの本文が表示されましたが、HTMLタグが混在していて見づらい状態ですね。
ここで、BeautifulSoupのcontents属性を使用して、要素の内容をより読みやすい形で表示することができます。
contents属性は、指定された要素の子要素をリストとして返します。
このリストには、テキストノードや他のHTMLタグなどが含まれます。
contentsを使用すると、HTMLタグの構造を保持しながらも、タグ自体は表示せずに内容だけを抽出することができます。
例えば、elemsの最初の要素の内容を表示するには、次のように実装します
if elems:
for content in elems[0].contents:
print(content)
else:
print("No elements found")このコードは、elems[0]の各子要素をループして、それぞれの内容を出力します。
これにより、HTMLタグを除外した純粋なテキストや他の要素の内容を確認することができます。
>>>出力結果
まず、株価を予測したい企業の4桁の株価コードを入力し、ファイル名を入力後に「株価データを取得」をクリックしてください。
クリック後にcsvファイルがダウンロードされます。その後、「ファイルを選択」をクリックし、先ほどダウンロードしたcsvファイルを選択してください。
「予測を開始」ボタンをクリックすることで、次の1ヶ月間の株価が現在よりも上昇するか下降するかを予測します。
<a href="/how_to_use">詳しい使い方とAI株価予測サービス概要についてはこちら</a>AI株価予測サービスの本文を取り出すことに成功した後、次はリンクのURLだけを取得することを目指します。
これを行うには、リンクを含むaタグのhref属性の内容を抽出します。
BeautifulSoupでは、attrs[‘href’]を使ってタグの属性値を取得することができます。
例えば、elemsリスト内の各要素に対してaタグを検索し、見つかった各aタグのhref属性を抽出するには、以下のように実装します
for elem in elems:
link = elem.find('a')
if link and 'href' in link.attrs:
print(link.attrs['href'])
else:
print("No link found")
>>>出力結果
/how_to_useこのコードは、elemsの各要素に対してfind(‘a’)を実行し、見つかったaタグからhref属性を抽出します。
この方法で、リンクのURLを単独で取得し、表示することが可能になります。
ここまででBeautifulSoupのselectメソッドを使用してCSSセレクタを利用し、指定されたAI株価予測サービスの本文とリンクを効率的に取得することができました。
selectメソッドは、HTMLドキュメント内でCSSセレクタに一致するすべての要素を検索し、それらをリストとして返します。これにより、特定の要素やデータを簡単かつ正確に取り出すことが可能となります。
findとfind_allメソッドの基本的な使い方(HTMLタグによる抽出)
次にfindとfind_allメソッドを使ってAI株価予測サービスのコラムタイトルとURLの組み合わせを抽出していきます
findもしくはfind_allメソッドを使った手順は次のとおりです
- ページのHTMLを取得:requestsライブラリなどを使用して、AI株価予測サービスのメインページのHTMLを取得します。
- BeautifulSoupオブジェクトを作成:取得したHTMLをBeautiful Soupオブジェクトに変換して、解析を行いやすくします。
- トップニュースを含むタグを特定:ページをブラウザで検証し、本文とURLを含むHTMLタグとそのクラス名を特定します。
- 必要な情報を抽出:特定したタグとクラス名を使用して、本文とURLを含む要素を検索
- 検索された各要素から、コラムタイトルとURLを抽出
findもしくはfind_all()メソッドを使ったスクレイピング
まずはHTMLデータを取得します
import requests
from bs4 import BeautifulSoup
url = 'https://aistock.tech/columns/beginercolumns'
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
>>>出力結果
<div class="container mt-5">
<h2 class="mb-4">株についての入門編コラム</h2>
<p>まずは株について基礎的な知識を身につけていきましょう</p>
<a class="term-card" href="/columns/beginercolumns/fundamentals_of_stock_investment">
<img alt="株式投資の基礎知識" src="/static/pictures/1.png"/>
<div class="term-card-content">
<div class="term-card-title">株式投資の基礎知識: 株式のイロハとは?</div>
<div class="term-card-description">入門編</div>
</div>
</a>
<a class="term-card" href="/columns/beginercolumns/start_investing_in_stocks">
<img alt="株式投資のスタート" src="/static/pictures/2.png"/>
<div class="term-card-content">
<div class="term-card-title">株式投資のスタート: どれくらいの金額から始められる?</div>
<div class="term-card-description">入門編</div>
</div>
</a>
<a class="term-card" href="/columns/beginercolumns/What_is_a_stock">
<img alt="株とは?" src="/static/pictures/3.png"/>
<div class="term-card-content">
<div class="term-card-title">「株」とは?「株式投資」の基礎知識</div>
<div class="term-card-description">入門編</div>
</div>
</a>
<a class="term-card" href="/columns/beginercolumns/profitable_stocks">
<img alt="儲かる株の探し方の基本" src="/static/pictures/7.png"/>
<div class="term-card-content">
<div class="term-card-title">「儲かる株」の探し方の基本</div>
<div class="term-card-description">入門編</div>
</div>
</a>
</footer>
<script src="/static/bootstrap-5.0.2-dist/js/bootstrap.bundle.min.js"></script>
</body>
</html>ここまではSelectメソッドを使用した時と同様です
実際に出力してみると、該当ページのHTMLが取得できていることがわかります
(※今回の出力結果では、一部のみ表示)
この情報を使って、欲しい情報を指定もしくは検索して取得していきますが、BeautifulSoupで欲しい情報を検索・指定するにはfindもしくはfind_allメソッドを使用します
| メソッド | 引数 | 説明 |
| find() | 検索するHTMLタグ | 引数に一致する 最初の1つの 要素を取得します。 |
| find_all() | 検索するHTMLタグ | 引数に一致する 全ての 要素を取得します。 |
AI株価予測サービスのコラム記事タイトルにカーソルを合わせて、右クリック。
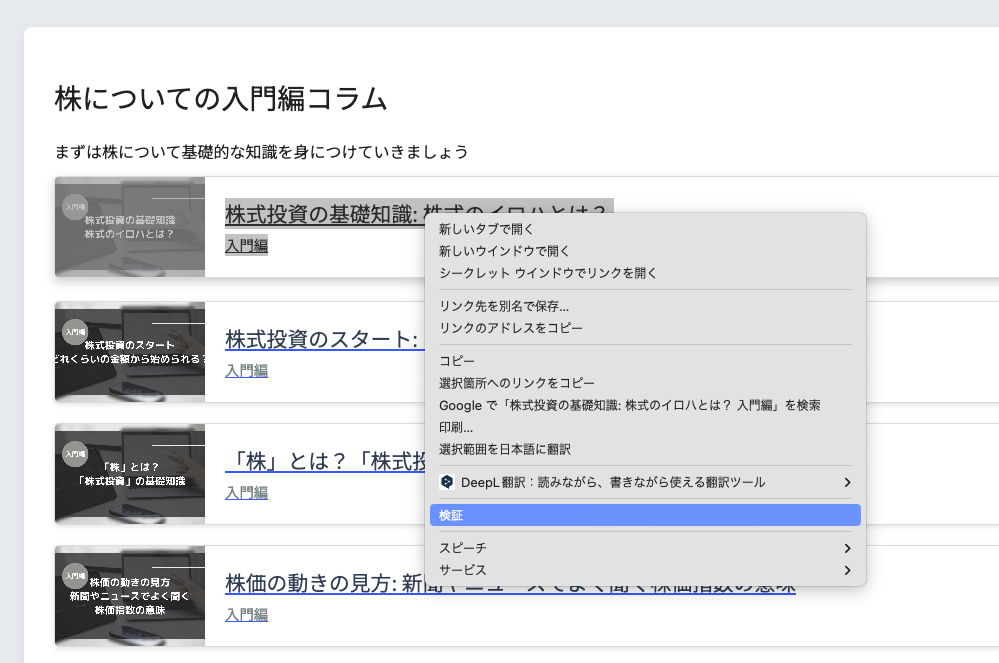
検証をクリックして、HTMLを表示します
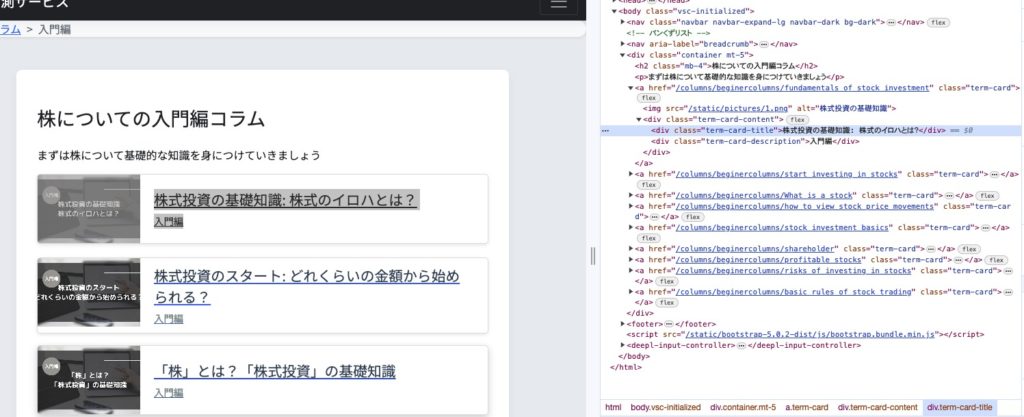
「株式投資の基礎知識:株式のイロハとは?」というタイトル上で検証をクリックすると、HTML構造の部分で、一行だけ色の違う部分があります
このHTMLはaタグで囲まれており、リンクの開始はhref属性でリンク先を指定しています
findもしくはfind_all()メソッドを使ったスクレイピングの解説
findメソッドを実行します
import requests
from bs4 import BeautifulSoup
url = 'https://aistock.tech/columns/beginercolumns'
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
elems = soup.find("a")
print(elems)
>>>出力結果
<a class="navbar-brand" href="/">AI株価予測サービス</a>今回のコードでは、ナビゲーションバー上にあるaタグが出力されており、欲しい情報を取得できていません
そこで、次にfind_all()メソッドを使って、aタグ全てを検索・取得します
import requests
from bs4 import BeautifulSoup
url = 'https://aistock.tech/columns/beginercolumns'
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
elems = soup.find_all("a")
print(elems)
>>>出力結果
[<a class="navbar-brand" href="/">AI株価予測サービス</a>, <a class="nav-link" href="/recommended_books">Python学習におすすめの書籍</a>, <a class="nav-link" href="/how_to_use">使い方</a>, <a class="nav-link" href="/columns">コラム</a>, <a class="nav-link" href="/glossary">専門用語の解説</a>, <a class="nav-link" href="/prediction_accuracy">株価予測精度について</a>, <a class="nav-link" href="/infotop">AI株価予測の結果</a>, <a class="nav-link" href="https://python-man.club/">Pythonに関するブログ</a>, <a href="/">ホーム</a>, <a href="/columns">コラム</a>, <a class="term-card" href="/columns/beginercolumns/fundamentals_of_stock_investment">
<img alt="株式投資の基礎知識" src="/static/pictures/1.png"/>
<div class="term-card-content">
<div class="term-card-title">株式投資の基礎知識: 株式のイロハとは?</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/start_investing_in_stocks">
<img alt="株式投資のスタート" src="/static/pictures/2.png"/>
<div class="term-card-content">
<div class="term-card-title">株式投資のスタート: どれくらいの金額から始められる?</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/What_is_a_stock">
<img alt="株とは?" src="/static/pictures/3.png"/>
<div class="term-card-content">
<div class="term-card-title">「株」とは?「株式投資」の基礎知識</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/how_to_view_stock_price_movements">
<img alt="株価の動きの見方" src="/static/pictures/4.png"/>
<div class="term-card-content">
<div class="term-card-title">株価の動きの見方: 新聞やニュースでよく聞く株価指数の意味</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/stock_investment_basics">
<img alt="なぜ株価は動くのか?" src="/static/pictures/5.png"/>
<div class="term-card-content">
<div class="term-card-title">株式投資の基本: なぜ株価は動くのか?</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/shareholder">
<img alt="株主になると得られる権利とは?" src="/static/pictures/6.png"/>
<div class="term-card-content">
<div class="term-card-title">株主になると得られる権利とは?</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/profitable_stocks">
<img alt="儲かる株の探し方の基本" src="/static/pictures/7.png"/>
<div class="term-card-content">
<div class="term-card-title">「儲かる株」の探し方の基本</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/risks_of_investing_in_stocks">
<img alt="株式投資のリスク" src="/static/pictures/8.png"/>
<div class="term-card-content">
<div class="term-card-title">株式投資のリスク:初心者が気をつけるポイント</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/basic_rules_of_stock_trading">
<img alt="株取引の基本ルール" src="/static/pictures/9.png"/>
<div class="term-card-content">
<div class="term-card-title">株取引の基本ルール:初心者が知っておくべきこと</div>
<div class="term-card-description">入門編</div>
</div>
</a>]このコードはfind_all()メソッドを使用しているため、すべての aタグを検索し、それぞれのコラムタイトルとhref属性(リンク先URL)、ナビゲーションバーのタイトルとhref属性を出力します。
一方で、find()メソッドにaを引数として渡すと、BeautifulSoupはHTML内で最初に見つかった a タグの要素を返します
find()メソッドは単一の要素を返すので、検索結果は最初に見つかった aタグに限定されます。
find_all()メソッドで情報を取得することができましたが、ここからさらに必要な情報だけに絞っていきます
先ほどの出力結果をもう一度見てみましょう
[<a class="navbar-brand" href="/">AI株価予測サービス</a>, <a class="nav-link" href="/recommended_books">Python学習におすすめの書籍</a>, <a class="nav-link" href="/how_to_use">使い方</a>, <a class="nav-link" href="/columns">コラム</a>, <a class="nav-link" href="/glossary">専門用語の解説</a>, <a class="nav-link" href="/prediction_accuracy">株価予測精度について</a>, <a class="nav-link" href="/infotop">AI株価予測の結果</a>, <a class="nav-link" href="https://python-man.club/">Pythonに関するブログ</a>, <a href="/">ホーム</a>, <a href="/columns">コラム</a>, <a class="term-card" href="/columns/beginercolumns/fundamentals_of_stock_investment">
<img alt="株式投資の基礎知識" src="/static/pictures/1.png"/>
<div class="term-card-content">
<div class="term-card-title">株式投資の基礎知識: 株式のイロハとは?</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/start_investing_in_stocks">
<img alt="株式投資のスタート" src="/static/pictures/2.png"/>
<div class="term-card-content">
<div class="term-card-title">株式投資のスタート: どれくらいの金額から始められる?</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/What_is_a_stock">
<img alt="株とは?" src="/static/pictures/3.png"/>
<div class="term-card-content">
<div class="term-card-title">「株」とは?「株式投資」の基礎知識</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/how_to_view_stock_price_movements">
<img alt="株価の動きの見方" src="/static/pictures/4.png"/>
<div class="term-card-content">
<div class="term-card-title">株価の動きの見方: 新聞やニュースでよく聞く株価指数の意味</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/stock_investment_basics">
<img alt="なぜ株価は動くのか?" src="/static/pictures/5.png"/>
<div class="term-card-content">
<div class="term-card-title">株式投資の基本: なぜ株価は動くのか?</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/shareholder">
<img alt="株主になると得られる権利とは?" src="/static/pictures/6.png"/>
<div class="term-card-content">
<div class="term-card-title">株主になると得られる権利とは?</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/profitable_stocks">
<img alt="儲かる株の探し方の基本" src="/static/pictures/7.png"/>
<div class="term-card-content">
<div class="term-card-title">「儲かる株」の探し方の基本</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/risks_of_investing_in_stocks">
<img alt="株式投資のリスク" src="/static/pictures/8.png"/>
<div class="term-card-content">
<div class="term-card-title">株式投資のリスク:初心者が気をつけるポイント</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/basic_rules_of_stock_trading">
<img alt="株取引の基本ルール" src="/static/pictures/9.png"/>
<div class="term-card-content">
<div class="term-card-title">株取引の基本ルール:初心者が知っておくべきこと</div>
<div class="term-card-description">入門編</div>
</div>
</a>]そうすると「/columns/beginercolumns/」という部分がコラムタイトルで共通であることがわかります
そこで、URLに「/columns/beginercolumns/」を含むという条件で情報を絞り込んでいきます
特定の文字列に一致しているかどうかを検索するにはreモジュールを使用します
import requests
from bs4 import BeautifulSoup
import re
url = 'https://aistock.tech/columns/beginercolumns'
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
elems = soup.find_all(href=re.compile("/columns/beginercolumns/"))
print(elems)
>>>出力結果
[<a class="term-card" href="/columns/beginercolumns/fundamentals_of_stock_investment">
<img alt="株式投資の基礎知識" src="/static/pictures/1.png"/>
<div class="term-card-content">
<div class="term-card-title">株式投資の基礎知識: 株式のイロハとは?</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/start_investing_in_stocks">
<img alt="株式投資のスタート" src="/static/pictures/2.png"/>
<div class="term-card-content">
<div class="term-card-title">株式投資のスタート: どれくらいの金額から始められる?</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/What_is_a_stock">
<img alt="株とは?" src="/static/pictures/3.png"/>
<div class="term-card-content">
<div class="term-card-title">「株」とは?「株式投資」の基礎知識</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/how_to_view_stock_price_movements">
<img alt="株価の動きの見方" src="/static/pictures/4.png"/>
<div class="term-card-content">
<div class="term-card-title">株価の動きの見方: 新聞やニュースでよく聞く株価指数の意味</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/stock_investment_basics">
<img alt="なぜ株価は動くのか?" src="/static/pictures/5.png"/>
<div class="term-card-content">
<div class="term-card-title">株式投資の基本: なぜ株価は動くのか?</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/shareholder">
<img alt="株主になると得られる権利とは?" src="/static/pictures/6.png"/>
<div class="term-card-content">
<div class="term-card-title">株主になると得られる権利とは?</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/profitable_stocks">
<img alt="儲かる株の探し方の基本" src="/static/pictures/7.png"/>
<div class="term-card-content">
<div class="term-card-title">「儲かる株」の探し方の基本</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/risks_of_investing_in_stocks">
<img alt="株式投資のリスク" src="/static/pictures/8.png"/>
<div class="term-card-content">
<div class="term-card-title">株式投資のリスク:初心者が気をつけるポイント</div>
<div class="term-card-description">入門編</div>
</div>
</a>, <a class="term-card" href="/columns/beginercolumns/basic_rules_of_stock_trading">
<img alt="株取引の基本ルール" src="/static/pictures/9.png"/>
<div class="term-card-content">
<div class="term-card-title">株取引の基本ルール:初心者が知っておくべきこと</div>
<div class="term-card-description">入門編</div>
</div>
</a>]さらにここからコラムタイトルとURLだけに絞って情報を取得していきます
import requests
from bs4 import BeautifulSoup
import re
url = 'https://aistock.tech/columns/beginercolumns'
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
elems = soup.find_all(href=re.compile("/columns/beginercolumns/"))
# 各要素からタイトルとURLを抽出
for elem in elems:
title = elem.find('div', class_='term-card-title').get_text(strip=True)
href = elem.get('href')
print(f"タイトル: {title}, URL: {href}")
>>>出力結果
タイトル: 株式投資の基礎知識: 株式のイロハとは?, URL: /columns/beginercolumns/fundamentals_of_stock_investment
タイトル: 株式投資のスタート: どれくらいの金額から始められる?, URL: /columns/beginercolumns/start_investing_in_stocks
タイトル: 「株」とは?「株式投資」の基礎知識, URL: /columns/beginercolumns/What_is_a_stock
タイトル: 株価の動きの見方: 新聞やニュースでよく聞く株価指数の意味, URL: /columns/beginercolumns/how_to_view_stock_price_movements
タイトル: 株式投資の基本: なぜ株価は動くのか?, URL: /columns/beginercolumns/stock_investment_basics
タイトル: 株主になると得られる権利とは?, URL: /columns/beginercolumns/shareholder
タイトル: 「儲かる株」の探し方の基本, URL: /columns/beginercolumns/profitable_stocks
タイトル: 株式投資のリスク:初心者が気をつけるポイント, URL: /columns/beginercolumns/risks_of_investing_in_stocks
タイトル: 株取引の基本ルール:初心者が知っておくべきこと, URL: /columns/beginercolumns/basic_rules_of_stock_tradingtitle = elem.find('div', class_='term-card-title').get_text(strip=True)この行では、各タグ(elem)内でクラス名が term-card-titleのタグを探します。
見つかったら、そのテキスト内容であるコラムタイトルを取得します。
get_text(strip=True)上記のコードは、テキストから余分な空白や改行を削除しています。
href = elem.get('href')ここでは、現在の タグ(elem)の href 属性を取得しています。これは、コラムのURL(相対パス形式)です。
これでコラムタイトルと記事URLを取得することができました
スクレイピングはWebサイトの利用規約によって、利用できるWebサイトとそうでないサイトに分かれるので、スクレイピングを行う際には注意が必要です
しかし、Webスクレイピングをうまく行うことができるようになると、以下のようなことも行うことができます
多すぎるキャンペーンを監視してキャンペーンが開始したらメールで通知するプログラム
PythonでスクレイピングするWebサイト(Web Scraper)を作ったよ
階層化されたサイトでスクレイピングで情報収集
どのWebサイトも階層化されているのが、一般的です
例えば、トップページ→(ジャンル)音楽→(ハードウェア)Apple、みたいな感じで、トップページから自分の求めているページに辿り着くまでに、いくつかのページを移動していかなければいけません
今回もAI株価予測サービスを使って、トップページからより深層にあるコラム記事の本文を取得していきたいと思います
階層化されたサイトのスクレイピング
まずはトップページからコラムのあるページURLを取得していきます
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import re
base_url = 'https://aistock.tech/'
response = requests.get(base_url)
soup = BeautifulSoup(response.text, 'html.parser')
columns_link = soup.find('a', string='コラム')
if not columns_link:
print("「コラム」のリンクが見つかりませんでした。")
else:
columns_url = urljoin(base_url, columns_link['href'])
print(f"コラムのURL: {columns_url}")
>>>出力結果
コラムのURL: https://aistock.tech/columns最初に取得したHTML内に「コラム」という文字列を含むURLを探して、見つかった場合には、出力を行っています
columns_url = urljoin(base_url, columns_link['href'])ここのコードは、コラムを含むURLとbase_urlを結合して、「https://aistock.tech/columns」というURLを作成しています
もし、結合をしなければ、「/columns」というURLのみだけになってしまい、それ以降のコードが正常に機能しません
これでコラムのURLを取得することが出来ました
コラムページは、入門編や基礎編などいくつかに分けられています
そのため、「https://aistock.tech/columns」を含むURLを取得していきたいと思います
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import re
base_url = 'https://aistock.tech/'
response = requests.get(base_url)
soup = BeautifulSoup(response.text, 'html.parser')
columns_link = soup.find('a', string='コラム')
if not columns_link:
print("「コラム」のリンクが見つかりませんでした。")
else:
columns_url = urljoin(base_url, columns_link['href'])
print(f"コラムのURL: {columns_url}")
response = requests.get(columns_url)
soup = BeautifulSoup(response.text, 'html.parser')
for link in soup.find_all('a', href=True):
href = link.get('href')
if '/columns/' in href and href != '/columns/':
subcategory_url = urljoin(columns_url, href)
print(f"サブカテゴリURL: {subcategory_url}")
>>>出力結果
コラムのURL: https://aistock.tech/columns
サブカテゴリURL: https://aistock.tech/columns/beginercolumns
サブカテゴリURL: https://aistock.tech/columns/minorrcolumns
サブカテゴリURL: https://aistock.tech/columns/middlecolumns
サブカテゴリURL: https://aistock.tech/columns/expertrcolumns
サブカテゴリURL: https://aistock.tech/columns/aistock最後に、最初に出力されたサブカテゴリURLから「https://aistock.tech/columns/beginercolumns」を含む記事タイトルとURLを取得するようにコーディングしていきます
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import re
base_url = 'https://aistock.tech/'
response = requests.get(base_url)
soup = BeautifulSoup(response.text, 'html.parser')
columns_link = soup.find('a', string='コラム')
if not columns_link:
print("「コラム」のリンクが見つかりませんでした。")
else:
columns_url = urljoin(base_url, columns_link['href'])
print(f"コラムのURL: {columns_url}")
response = requests.get(columns_url)
soup = BeautifulSoup(response.text, 'html.parser')
for link in soup.find_all('a', href=True):
href = link.get('href')
if '/columns/' in href and href != '/columns/':
subcategory_url = urljoin(columns_url, href)
print(f"サブカテゴリURL: {subcategory_url}")
# サブカテゴリ内のコラム記事のURLを探す
response = requests.get(subcategory_url)
soup = BeautifulSoup(response.text, 'html.parser')
article_links = soup.find_all('a', href=re.compile(r'/columns/.+/'))
if article_links:
for article_link in article_links:
article_url = urljoin(subcategory_url, article_link['href'])
article_title = article_link.find('div', class_='term-card-title').get_text(strip=True)
print(f"コラム記事タイトル: {article_title}, URL: {article_url}")
else:
print("このサブカテゴリにはコラム記事がありません。")
break
>>>出力結果
コラムのURL: https://aistock.tech/columns
サブカテゴリURL: https://aistock.tech/columns/beginercolumns
コラム記事タイトル: 株式投資の基礎知識: 株式のイロハとは?, URL: https://aistock.tech/columns/beginercolumns/fundamentals_of_stock_investment
コラム記事タイトル: 株式投資のスタート: どれくらいの金額から始められる?, URL: https://aistock.tech/columns/beginercolumns/start_investing_in_stocks
コラム記事タイトル: 「株」とは?「株式投資」の基礎知識, URL: https://aistock.tech/columns/beginercolumns/What_is_a_stock
コラム記事タイトル: 株価の動きの見方: 新聞やニュースでよく聞く株価指数の意味, URL: https://aistock.tech/columns/beginercolumns/how_to_view_stock_price_movements
コラム記事タイトル: 株式投資の基本: なぜ株価は動くのか?, URL: https://aistock.tech/columns/beginercolumns/stock_investment_basics
コラム記事タイトル: 株主になると得られる権利とは?, URL: https://aistock.tech/columns/beginercolumns/shareholder
コラム記事タイトル: 「儲かる株」の探し方の基本, URL: https://aistock.tech/columns/beginercolumns/profitable_stocks
コラム記事タイトル: 株式投資のリスク:初心者が気をつけるポイント, URL: https://aistock.tech/columns/beginercolumns/risks_of_investing_in_stocks
コラム記事タイトル: 株取引の基本ルール:初心者が知っておくべきこと, URL: https://aistock.tech/columns/beginercolumns/basic_rules_of_stock_trading欲しい情報がトップページ以外にある場合には、欲しい情報の文字列をプログラムに組み込んで、その文字列に一致した情報のみを抽出するのがいいです
Selectメソッドを使うには、HTMLからセレクターを選ぶ必要がありますが、reモジュールを使って、文字列の検索を使えば、手軽に情報を収集できます
まとめ
スクレイピングを行えるようになると、さまざまなデータ収集を自動化することができ、業務効率に繋がります
一方で、サイトによってはスクレイピングを禁止している場所もあるため、スクレイピングを行う場合には、規約違反にならないよう注意が必要です
Pythonでスクレイピングを行うなら、3つのライブラリは扱えるようになっておくといいでしょう
- BeautifulSoup
- Requests
- Selenium
BeautifulSoup,Requests,Seleniumの全て効率よく学びたい方は、Pythonによるビジネスに役立つWebスクレイピングがおすすめです
HTMLの基本から、実際のデータ取得まで一貫して学ぶことが出来ます







