
pythonを使ってデータ分析をできる様になりたい。
一からpythonを学び始めてデータ分析ができるようになるのか知りたい
こういった疑問に答えます
筆者について
2021年から本格的にPython学習を始め、今ではPythonによる収益化に成功
大学院時代には、R言語とPythonを使って統計処理を行っていたため、Pythonを使ったデータサイエンスの知識が豊富
医療データを機械学習を用いて解析したり、学会発表も行なっている
Pythonで機械学習を始めたい方は、こちらを参考にしてください

Contents
Pythonでデータ分析を行うまでの流れを知る
Pythonを使ってデータ分析を行うためには、pythonでデータ分析を行うまでの流れを知りましょう
大まかな流れとしては
- データの読み込み
- データの加工
- データの統計処理
- データの可視化
- モデルの作成
- モデルの評価
- モデルの可視化
となります
一つずつ解説していきますが、必要のない部分は飛ばして行っても大丈夫です
モデルの作成以降は、機械学習の分野になってきますが、Pythonでデータ分析を行うのであれば、機械学習も身につけておいた方が、これからの時代に重宝されます
データの読み込み
 データ分析を行うためのデータを読み込みましょう
データ分析を行うためのデータを読み込みましょう
読み込むには以下のコードを使用すればOKです
今回はseabornに含まれているirisのデータを使って統計解析を行なってみたいと思います
import pandas as pd
import seaborn as sns
sns.set()
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
print(iris.head())
>>>
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosaデータの加工
 実際のデータになると欠損値が含まれていたり、不要なデータが含まれていることがあります
実際のデータになると欠損値が含まれていたり、不要なデータが含まれていることがあります
欠損値を削除するには以下のコードを使用すればOKです
irisデータでは欠損値がないので、コードの意味だけ理解しておきましょう
iris.dropna(how='any')欠損値の処理として、引数を変更することで削除するものが変わってきます
- dropna(how=’all’):すべての値が欠損値である行・列を削除
- dropna(how=’any’):欠損値が1つでも含まれる行・列を削除
- dropna(how=’thresh’):欠損値ではない要素の数に応じて行・列を削除
- dropna(subset=[‘name’]):特定の行・列に欠損値がある行・列を削除
統計処理を行う前に、ここでデータの分布を確認しておきます
正規性の検定と呼ばれるものです
コードはこちらでOKです
import pandas as pd
import seaborn as sns
sns.set()
from scipy import stats
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
A=iris.iloc[:,2]
B=iris.iloc[:,3]
result=stats.shapiro(A)
result=stats.shapiro(B)詳細はこちらの記事を参考にしてください

データの統計処理
 データ整形が終わったら、実際に統計処理を行います
データ整形が終わったら、実際に統計処理を行います
今回は2群比較をしたいと思います
正規性の確認をしていますが、今回はノンパラメトリック検定を行います
対応しているデータの場合には、ウィルコクソンの符号付き順位検定をかけます
import pandas as pd
import seaborn as sns
sns.set()
from scipy import stats
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
A=iris.iloc[:,2]
B=iris.iloc[:,3]
result=stats.wilcoxon(A, B, alternative='two-sided')対応していないデータの場合には、マンホイットニーのU検定をかけます
import pandas as pd
import seaborn as sns
sns.set()
from scipy import stats
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
A=iris.iloc[:,2]
B=iris.iloc[:,3]
result=stats.mannwhitneyu(A, B, alternative='two-sided')データの対応の有無については、こちらを確認してください
>>>データの対応の有無とは?(…coming soon…)
それ以外の統計検定については、こちらを参考にしてください
データの可視化
 統計処理まで終わったら、データの可視化を行います
統計処理まで終わったら、データの可視化を行います
seabornを使用した方が綺麗なグラフを作成することができるので、seabornを使用していきます
from matplotlib import pyplot as plt
import seaborn as sns; sns.set()
#あらかじめ用意されているirisのデータを使用
iris = sns.load_dataset('iris')
sns.distplot(
iris['sepal_width'], bins=13, label='data',
kde=False,
rug=False
)
plt.legend() # 凡例を表示
plt.show() # ヒストグラムを表示また、平均値を算出して、それをグラフ化するには以下のコードを入力します
from matplotlib import pyplot as plt
import seaborn as sns; sns.set()
import pandas as pd
#あらかじめ用意されているirisのデータを使用
iris = sns.load_dataset('iris')
sepal_length=iris.iloc[:,0]
sepal_width=iris.iloc[:,1]
print(sepal_length.mean(),sepal_width.mean())
data=[["iris",sepal_length.mean(),sepal_width.mean()]]
df=pd.DataFrame(data,columns=["name","sepal_length","sepal_width"])
color=["r","b"]
df.plot(x="name",y=["sepal_length","sepal_width"],kind="bar",color=color,figsize=(4,3))
plt.show()可視化の詳細は、以下の記事で解説をしています

モデルの作成
続いて、モデルの作成を行なっていきます
そもそもモデルって何?というところからですが、モデルというのは、入力されたデータを解析し、評価・判定を行う過程になります
例えば、大量の受信メールの中から、特定のフレーズやワードを学習し、迷惑メールに振り分ける、といった過程があった場合、特定のフレーズやワードを学習するのがモデルになります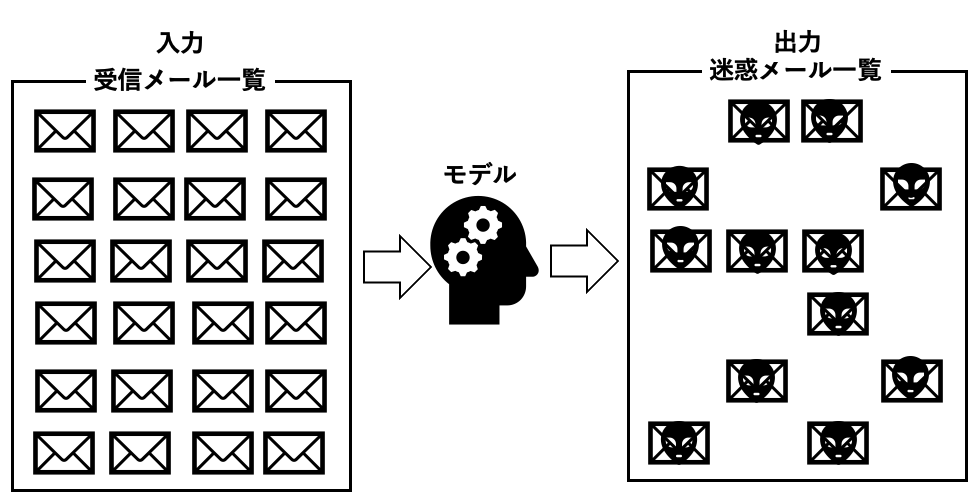
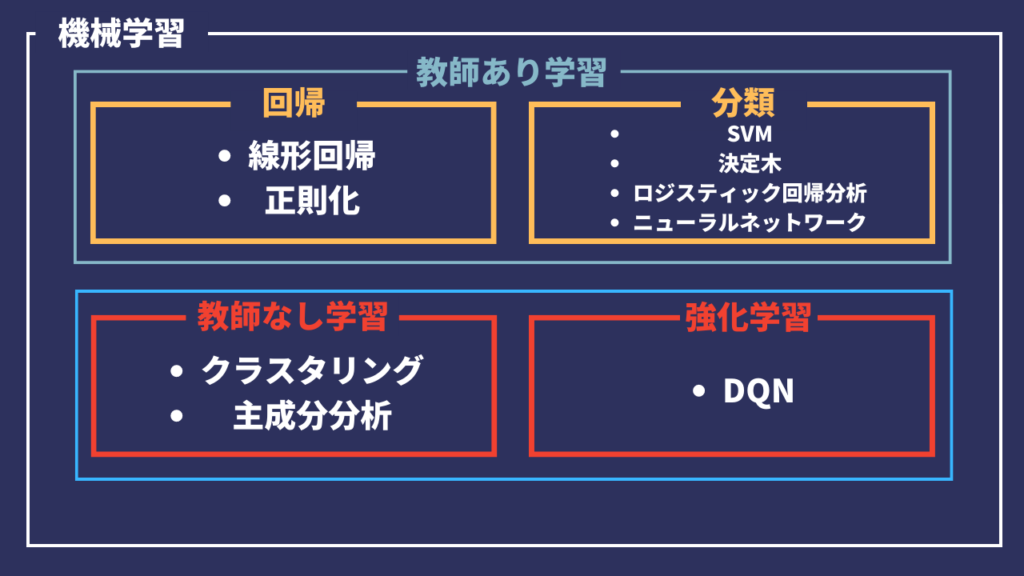
機械学習の学習モデルはいくつかあります
- 線形回帰
- 正則化
- サポートベクターマシン(SVM)
- 決定木・ランダムフォレスト
- k近傍法
- ロジスティック回帰
- ニューラルネットワーク
- クラスタリング
- 次元削減 (PCA : 主成分分析)
- DQN
上記の学習モデルをおおまかに分けると、次のようになります
今回は線形回帰のサンプルコードを提示します
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# サンプルデータの作成
np.random.seed(0)
X = np.random.rand(100, 1)
y = 2 * X + 1 + 0.1 * np.random.randn(100, 1)
# データを訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 線形回帰モデルのインスタンスを作成
model = LinearRegression()
# モデルの訓練
model.fit(X_train, y_train)
# モデルの予測
y_pred = model.predict(X_test)
# モデルの評価
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean squared error: {mse:.2f}")
print(f"R2 score: {r2:.2f}")
# 結果の可視化
plt.scatter(X_test, y_test, color='blue', label='Actual')
plt.scatter(X_test, y_pred, color='red', label='Predicted')
plt.plot(X_test, y_pred, color='red')
plt.legend()
plt.xlabel('X')
plt.ylabel('y')
plt.show()
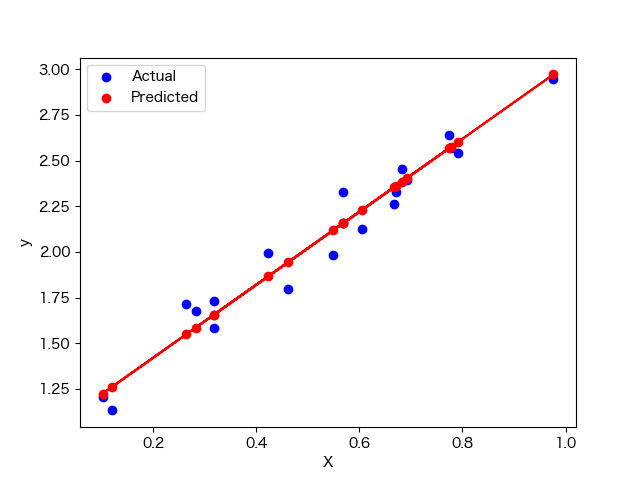
モデルの評価
機械学習のモデル評価は、さまざまな方法があります
線形回帰のサンプルコードでは、平均二乗誤差とR2スコアを算出しています
1.分類問題の評価指標:
- 正解率 (Accuracy)
- 適合率 (Precision)
- 再現率 (Recall)
- F1スコア (F1 Score)
- AUC-ROCカーブ (Area Under the Receiver Operating Characteristic Curve)
2.回帰問題の評価指標:
- 平均二乗誤差 (Mean Squared Error, MSE)
- 平均絶対誤差 (Mean Absolute Error, MAE)
- R2スコア (R-squared, Coefficient of Determination)
3.クラスタリング問題の評価指標:
- シルエットスコア (Silhouette Score)
- カルインスキ・ハラバスズ指数 (Calinski-Harabasz Index)
- デイビス・ボールドイン指数 (Davies-Bouldin Index)
モデルの可視化
最後に機械学習モデルの可視化を行なっていきます
可視化を行うには、matplotlibやseabornを使用するのが一般的です
サンプルコードで提示している線形回帰もmatplotlibで可視化をしています
可視化を行うメリットとして、モデルの理解や解釈を容易にすることができます
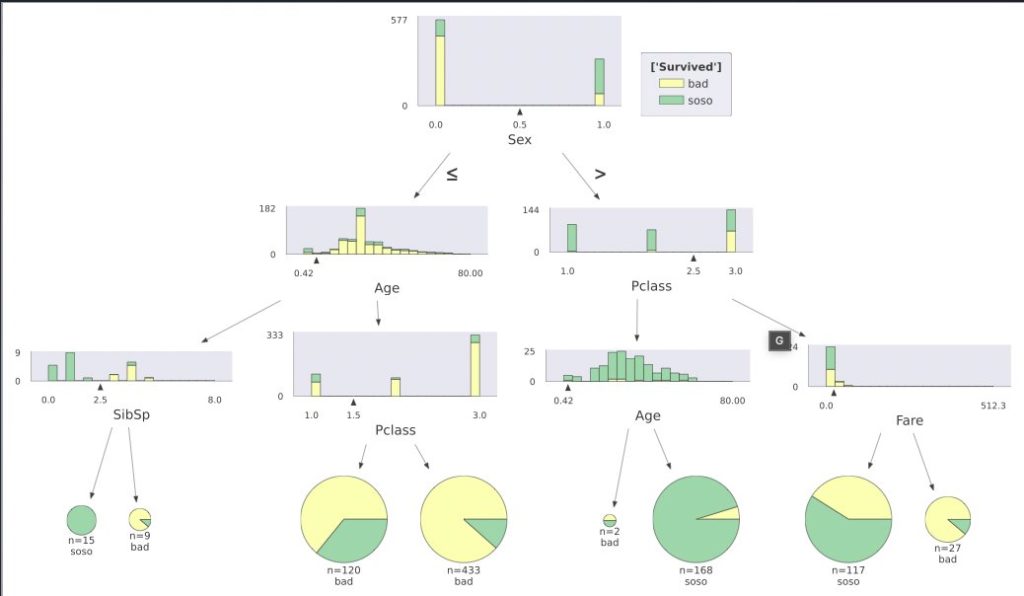
機械学習モデルの可視化には、matplotlibやseaborn以外にも、決定木を可視化する「dtreeviz」というライブラリもあり、このような可視化を行うことができます
pythonでデータ分析を行うための環境構築をする

Pythonでデータ分析を行うためには、まず環境構築をする必要があります
データ分析を行うのであれば、Anacondaを使用するのがおすすめです
Anacondaの詳細は以下の記事を参考にしてください

Anacondaのインストール

Anacondaの起動
「Launhpad」から「Anaconda-Navigator」を起動します

下記のような画面が表示されたら、起動完了となります。
Anacondaをインストールするには、下記のサイトから行います
https://www.anaconda.com/products/individual
 downloadをクリック
downloadをクリック 続けるをクリック
続けるをクリック 続けるをクリック
続けるをクリック 続けるをクリック
続けるをクリック 同意するをクリック
同意するをクリック 特定のディスクにインストールを選択
特定のディスクにインストールを選択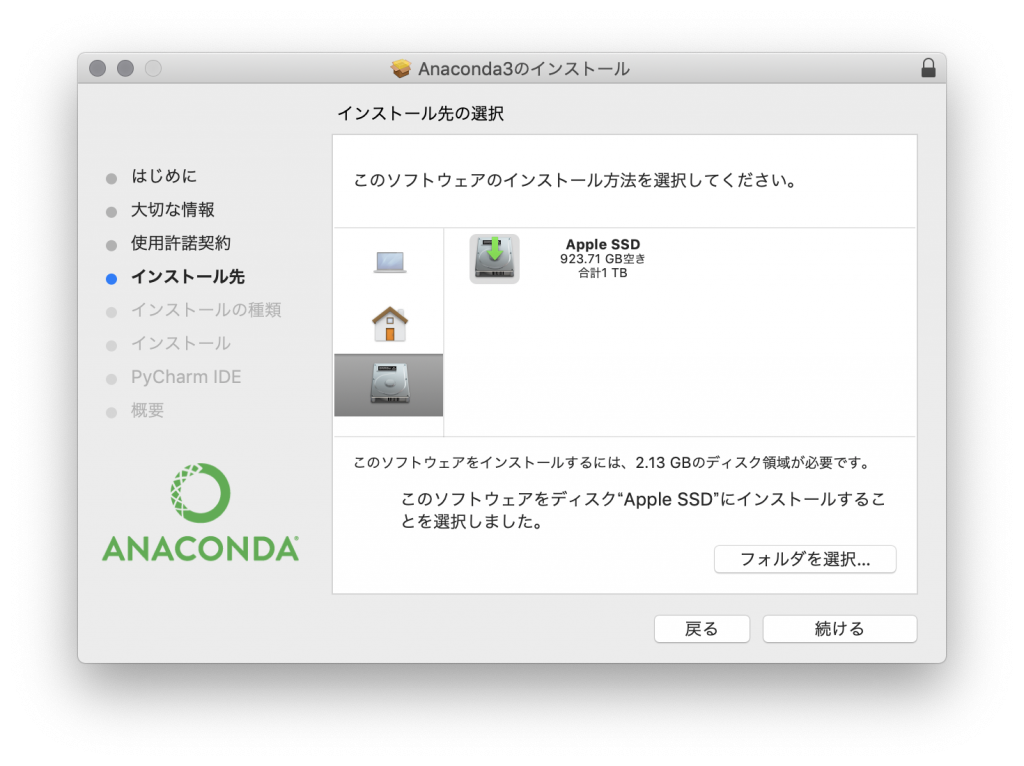 続けるをクリック
続けるをクリック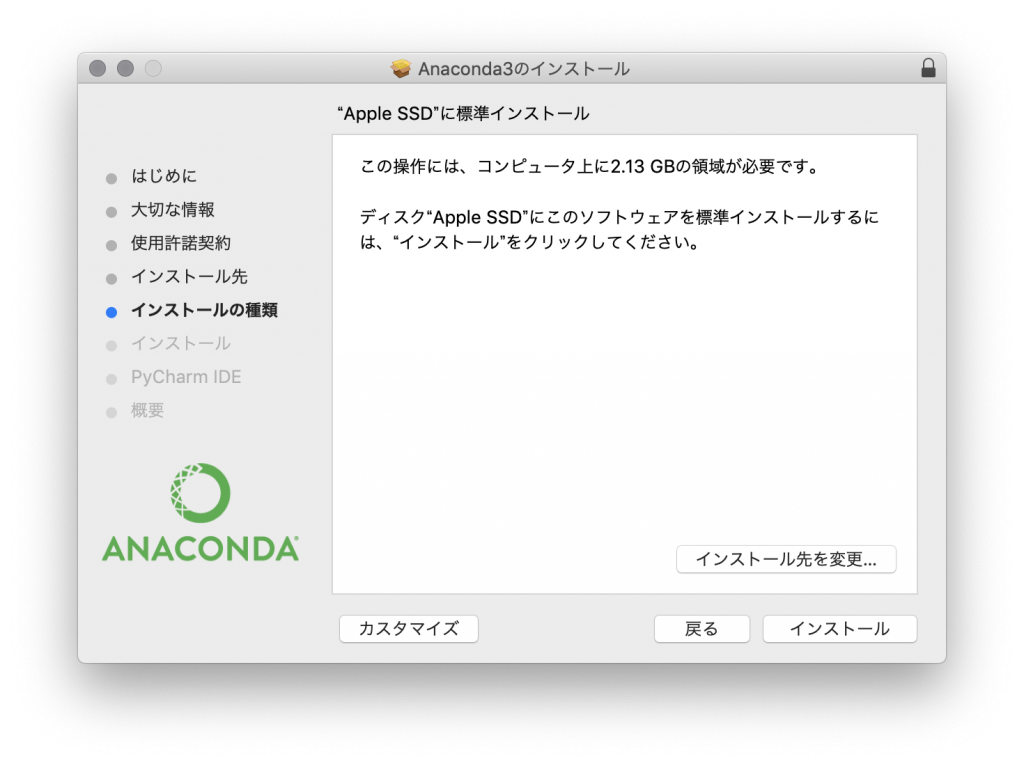 インストールをクリック
インストールをクリック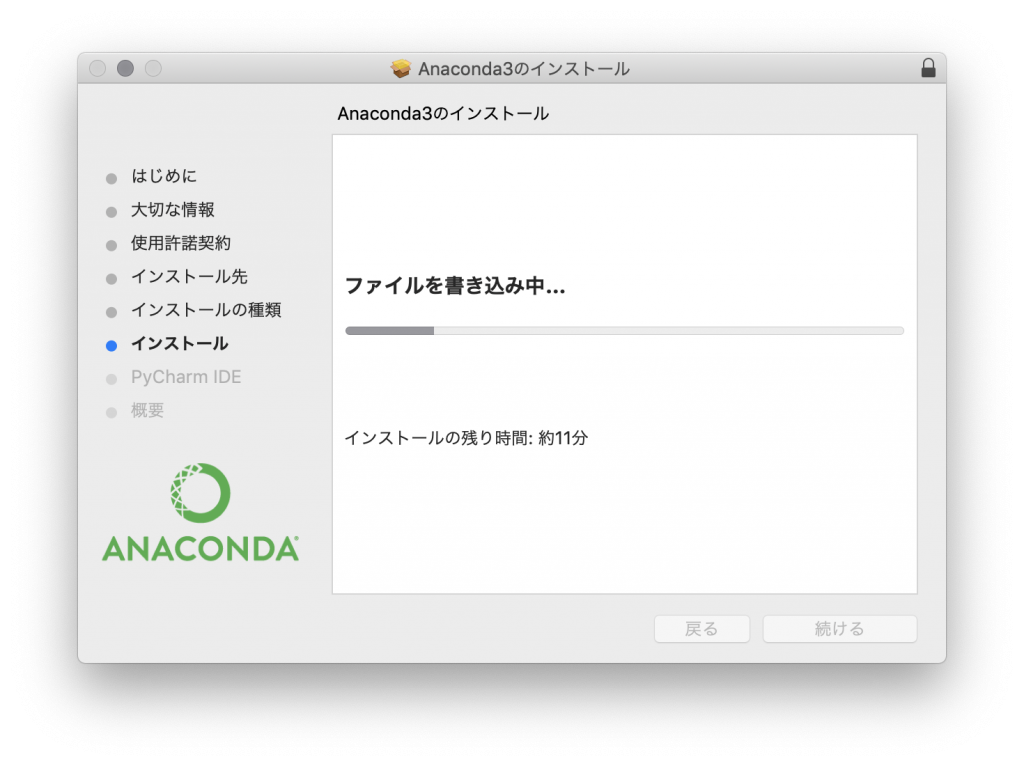 インストールが完了するのを待ちます
インストールが完了するのを待ちます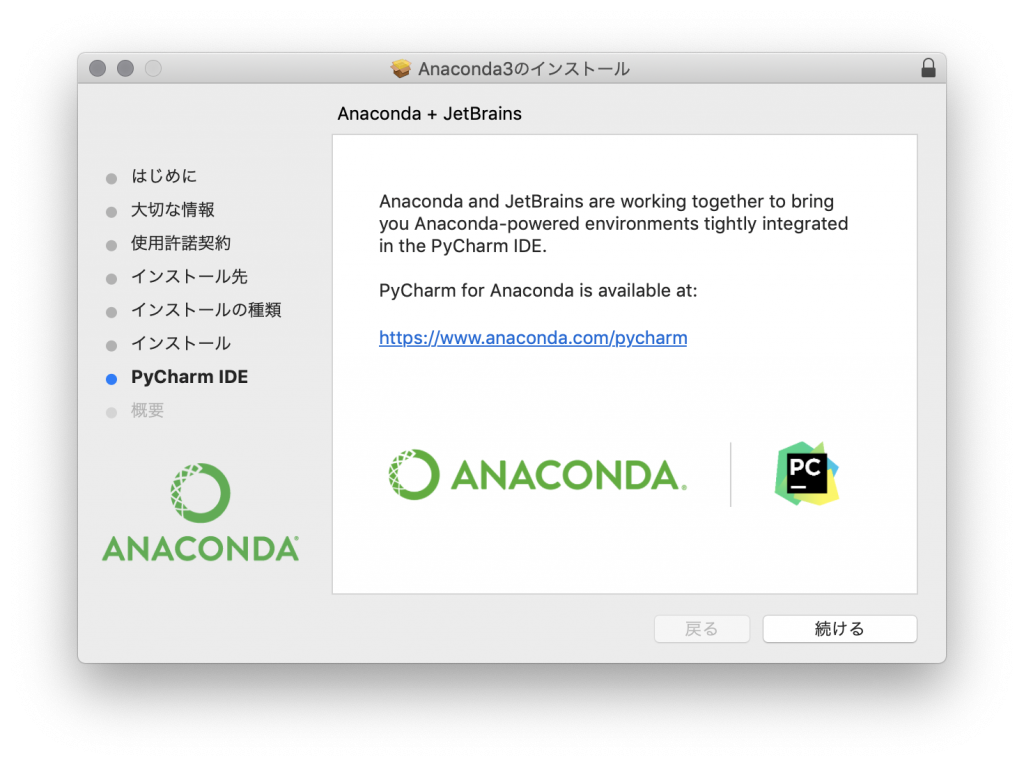 続けるをクリック
続けるをクリック 閉じるをクリック
閉じるをクリックAnacondaの起動
「Launhpad」から「Anaconda-Navigator」を起動します
下記のような画面が表示されたら、起動完了となります。
spyderの導入

Anacondaをインストールしたら、spyderをlaunchします
Launchの方法は簡単です
「Anaconda-Navigator」から「Spyder」を起動します
Spyderについて、詳しい解説はこちらから

Spyderを起動すると以下のような画面になります
プログラムを書いて、実行すると、画面右下に実行結果が表示されます。
spyderでコードを書く

コードを書いていくのはspyderがおすすめです
Jupyter Notebookでコードを書いている人も多いと思いますが、僕のおすすめはspyerです
詳しい理由は以下の記事からどうぞ
pythonでデータ分析を行うための基本的なコードをマスターする
Pythonでデータ分析を行うには、データ分析のコードだけではなく、pythonの基本的な文法もマスターしておく必要があります
その都度マスターするのではなく、少しずつマスターしていけばOKです
実際に僕はそういうふうに行なってきました
Pythonで基本となる文法は繰り返し出てくるので、一度で理解しようとしなくで大丈夫です
おすすめwebサイト

僕が独学でpythonを学んだときに参考にしたwebサイトです
今では公式ドキュメントを見ることが多いですが、最初に公式ドキュメントを読んでも理解できないので、さまざまなサイトを訪れていました
以下のサイトは分かりやすいと思います
【基礎一覧】Pythonの基本文法を全て解説してみた!【初心者】
おすすめ書籍

書籍も何冊か購入しましたが、pythonでデータ分析を行うのであれば、以下の書籍は必読だと思います


おすすめスクール

Pythonを独学で学ぶのがきついor時間・金銭的な余裕がある場合には、スクールに通うのも一つの方法です
短い期間で一気にpythonの知識をつけることができます
以下のスクールは無料体験などもあるので、無料体験後に入会するかどうかを決めればOKです
python無料体験OK「テックジム」
テックジムでは無料のオンライン講座や校舎別講座を開いています。
この無料講座を通じて入会前にテックジムのカリキュラムに触れることで、納得して学習を開始することができます
無料セミナー開催の頻度も多く、東京以外でも全国のスクールで開催されています。
また、テックジムではTechGYM方式を採用しています
TechGYM方式とは、基礎知識・予備知識なしでも座学を利用しないでプログラミングに専念できるカリキュラムのことです。
従来の講義型の学習の場合、座学でプログラミングの基礎を学習してから実際に画面にコードを打ち込んでみる、という2段構えの学習スタイルが取られます。
しかし、TechGYM方式では演習の時間を多くとっているため、それだけ学習効率も高まります。
さらにテックジムはスクールとオンライン2種類を用意しているので、どこにいてもテックジムの講義を受けることができます。
無料体験などもあるので、ぜひこの機会に体験してみてください。
python無料体験OK「キカガク」
キカガク![]() の最大の特徴は国の補助金である教育訓練支援給付の対象となっているため、70%offになることです
の最大の特徴は国の補助金である教育訓練支援給付の対象となっているため、70%offになることです
これだけでもキカガク![]() を受講するメリットはあります。
を受講するメリットはあります。
さらにキカガク![]() は教育のプロ集団でもあるため、難しい部分を初学者にわかりやすく解説してくれるため、挫折が少なくてすみます。
は教育のプロ集団でもあるため、難しい部分を初学者にわかりやすく解説してくれるため、挫折が少なくてすみます。
また、オンラインのみなので、通学に時間をかけない分、それだけプログラミングに集中することもできます
無料体験もあるので、ぜひこの機会に体験してみてください。
![]()
python無料体験OK「.Pro」
.Proはあまり名前を聞いたことがない人がほとんどかと思います。
それは広告をあまり出しておらず、新規生徒数も10人と絞っているためです。
週一回対面授業があり、生徒10名に対して講師は4名程度付きます。
少数精鋭で行なっているからこそ、ここまで手厚いサポートが可能となります。
無料体験などもあるので、ぜひこの機会に体験してみてください。
いずれにおいても、やればやっただけプログラミングの能力は上がります
Pythonでデータ分析を行うための主要なライブラリを把握する

Pythonの基本的な文法をマスターすることができたら、あとはデータ分析を行うのに必要なライブラリを把握すればOKです
Pythonでデータ分析を行う際によく出てくるライブラリは以下です
- pandas
- numpy
- matplotlib
- scikit-learn
pandas

pandasでは基本的なデータ分析・解析を行うことができるライブラリです
データの読み込み・書き込みなどの前処理などができます
要約統計量の算出も可能

numpy

numpyは数値計算を行うことができるライブラリです
動作が高速なため、機械学習などでよく用いられています
matplotlib

データ可視化用のライブラリ
グラフ描画、画像表示などが可能
matplotlibよりseabornの方が綺麗なグラフを作成することができます
scikit-learn

機械学習用のライブラリ
学習モデルを作成し、予測や分類などに適応することが可能
実際にpythonでデータ分析を行なってみる
ここまでで一通りのデータ分析の流れを解説しました
実際にサンプルデータでデータ分析を行なっていきましょう
サンプルデータでデータ分析を行う

クラスタリングのサンプルコードは、以下の記事から実装することができます

また、線形回帰については、次のようになります
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# サンプルデータの作成
np.random.seed(0)
X = np.random.rand(100, 1)
y = 2 * X + 1 + 0.1 * np.random.randn(100, 1)
# データを訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 線形回帰モデルのインスタンスを作成
model = LinearRegression()
# モデルの訓練
model.fit(X_train, y_train)
# モデルの予測
y_pred = model.predict(X_test)
# モデルの評価
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean squared error: {mse:.2f}")
print(f"R2 score: {r2:.2f}")
# 結果の可視化
plt.scatter(X_test, y_test, color='blue', label='Actual')
plt.scatter(X_test, y_pred, color='red', label='Predicted')
plt.plot(X_test, y_pred, color='red')
plt.legend()
plt.xlabel('X')
plt.ylabel('y')
plt.show()
勉強効率を高める教材

Webサイトだけではうまく学習が進まない場合には、以下のコンテンツを使用することで、pythonの学習効率を高めることができます
udemy
Udemyの基本情報
・世界最大のオンライン学習プラットフォーム
・日本事業ではベネッセがパートナーになっている
・15万種類ものコース
・約3億人のユーザー登録
ドットインストール
ドットインストールは、動画を見ながら学べるサイト
学べる言語の幅や講座数が非常に多く、このようなサブスクリプションプログラミング学習サービス中では日本最大手
Aidemy
Aidemyの最大の特徴は国からの補助金で受講料が最大70%offになること
未経験からでも最短3ヶ月でAI・機械学習エンジニアとして転職可能なレベルのスキルを学べるサービスと口コミでも評判
テックアカデミー
完全オンライン完結のプログラミングスクール
コースは全部で29種類と豊富であり、質問に対して即レスで返事をくれると口コミでも評判
テラテイル
webで調べて、試行錯誤しても全くわからない…
っていう状況を打破してくれる、手助けしてくれるのが、テラテイル
実現したいこと・エラーメッセージ・コードなどを記載すれば、プロのエンジニアの方々が手助けをしてくれます
登録しておいて損はないサイトです
Python初心者はぜひ利用してみてください
kindle
Python学習を進めていく上で、
「ひとまず何かしらの書籍に目を通したい」
「webで調べても全くわからない」
という状況が何度も何度でも出てくるかと思います。
そういう時に便利なのが、kindleです
Kindleはご存知の通り、電子書籍です
Kindleには多くのpython学習本が用意されており、無料で読むことができます。
(たまに有料もあります)
ひとまずどういった書籍があるのか?
もしものために、書籍に目を通しておこう
という場合には、kindleの利用がおすすめです








