
近年、AI技術が進歩しており、さまざまなサービスがリリースされていますが、AI技術を支えているのは、機械学習・ディープラーニングと呼ばれる技術です
機械学習に用いられる技術の多くは、Pythonと呼ばれるプログラミング言語によって開発されていることが多く、AI開発を行いたい場合には、Pythonの学習が大切になります
この記事では、機会学習とはどういったものなのか?機械学習でどういったことができるのか、どのようにPythonで機械学習を学ぶのかについて、解説をしていきます。
本記事をお読みいただくことで、機械学習について知識を深めることができ、機械学習の学び方・実装方法を理解することができます
筆者について
2021年から本格的にPython学習を始め、今ではPythonによる収益化に成功
大学院時代には、R言語とPythonを使って統計処理を行っていたため、Pythonを使ったデータサイエンスの知識が豊富
医療データを機械学習を用いて解析したり、学会発表も行なっている
機械学習やAIでは、データサイエンスが非常に重要になります
データサイエンスについて学びたい場合には、キカガクの利用がおすすめです
キカガクは、初心者からAIエンジニアに転職可能なプログラミングスクールで、最新技術を学ぶことができます
無料個別相談会をオンラインで行っているので、興味がある方は一度参加してみるのをおすすめします
※無料オンライン相談や個別相談などさまざまなイベントが開催中
Contents
機械学習には3種類がある
 機械学習とは、人工知能を開発するための技術の1つです
機械学習とは、人工知能を開発するための技術の1つです
機械学習の定義は、データの解析を行い、データから学習した内容を応用し、十分な情報に基づく判断を下すアルゴリズム、とされています
AIの中に機械学習が含まれており、機械学習の中には、ディープラーニングが含まれています
そのため、AIと言ったときに、機械学習のことを指している場合もあれば、ディープラーニングを指している場合もあります
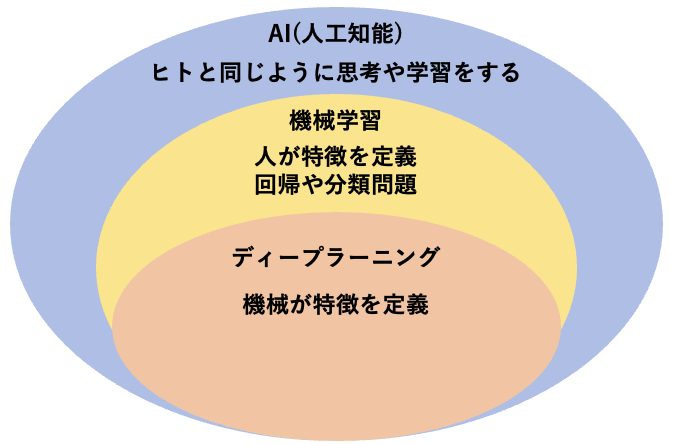
また、機械学習と一言で言っても、機械学習は大きく分けると3種類に分けることができます
- 教師あり学習
- 教師なし学習
- 強化学習
それぞれ次の項目で詳細に解説をしていきます
教師あり学習
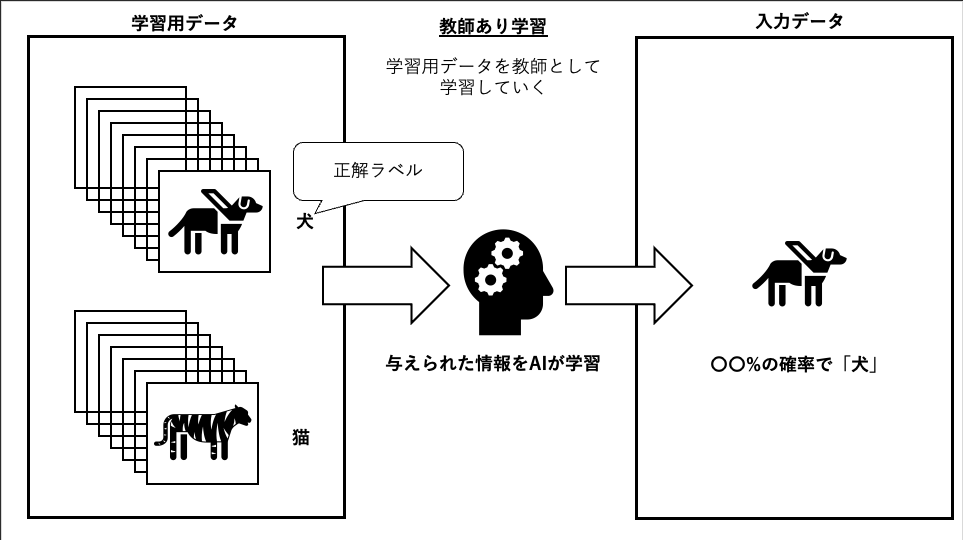
教師あり学習とは、プログラムに正解となる学習データを与え、学習させる手法です
学習データを教師として、与えられたデータで学習を進めていき、未知なるデータが入力されたときに、学習データに基づき、出力を予測するのが教師あり学習になります
すでに与えられているデータに「犬」や「猫」と名称をつけることを「ラベル付け」と呼びます
教師あり学習は、分類と回帰で使用されることが多く、画像認識や文章分類、音声認識などに活用されています
- 分類:入力データを複数に分けることが目的
- 回帰:入力データから連続的な出力値を予測するのが目的
Pythonで機械学習の教師あり学習を行う場合には、次のようなライブラリがあります
- scikit-learn:分類、回帰、クラスタリング、次元削減などの機械学習アルゴリズムを提供する優れたライブラリ
- TensorFlow:深層学習 (Deep Learning) アルゴリズムを提供する人気のライブラリ
- PyTorch:TensorFlowに代わる人気のDeep Learningフレームワーク
教師なし学習
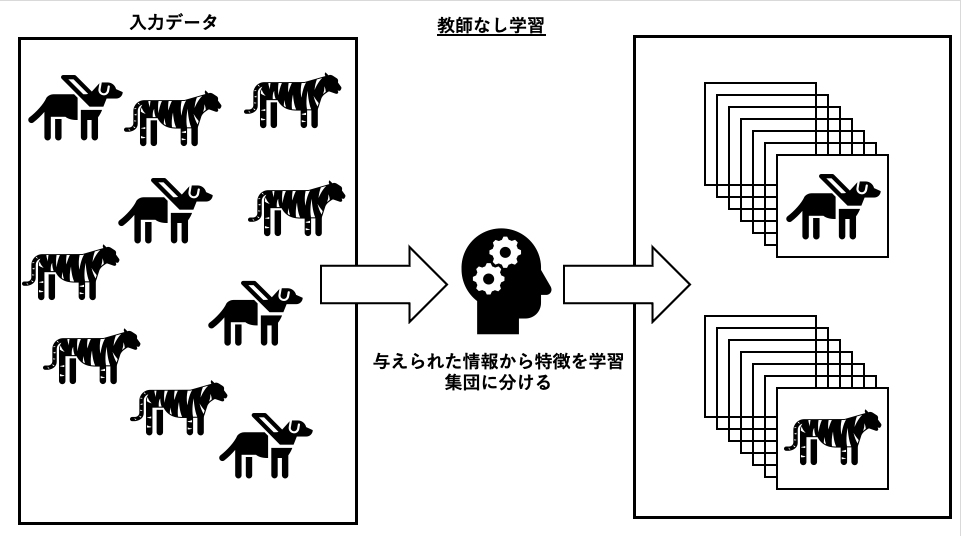
教師なし学習は、入力データにラベル付けがされておらず、与えられたデータに隠されている特徴や構造を学習します
学習した後に、いくつかに集団にグループ分けを行うのが、教師なし学習になります
このとき分けられたグループの特徴や構造がどういったものなのかは、データ解析者の判断が必要になります
教師なし学習はクラスタリングと次元削減などに活用されており、データ探索やデータ可視化、異常検知などで活用されています
- クラスタリング:入力データをグループに分けることを目的とします
- 次元削減:高次元データを低次元データに圧縮するのが目的です
Pythonで機械学習の教師なし学習を行う場合には、次のようなライブラリがあります
- scikit-learn:分類、回帰、クラスタリング、次元削減などの機械学習アルゴリズムを提供する優れたライブラリです。
- SciPy:数値計算、信号処理、統計などのライブラリの一つです。教師なし学習にも使われます。
- NumPy:数値計算を行うためのライブラリです。
クラスタリングの実装は、次の記事でサンプルコード付きで解説しているので、参考にしてください

強化学習
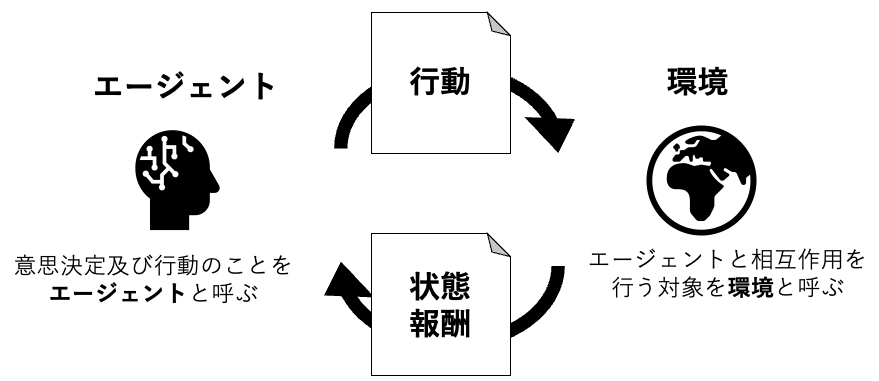
強化学習とは、エージェントが環境とやり取りをすることで、最適な行動を学習する機械学習です
強化学習では、エージェントが環境から受け取る報酬を最大化するように、行動を選択することで、学習を行なっていきます
強化学習には、様々なアルゴリズムがあります
例えば、「Q学習」は、行動を選択するためのQ値を求めることで、最適な行動を学習したり、「SARSA」は、状態と行動を同時に求めるアルゴリズムです
Pythonで強化学習を行うためのライブラリとして、次のようなものがあります
- OpenAI Gym:OpenAI Gymを使うことで、様々なタスクを設定して、エージェントを学習させることができます
- stable-baselines:OpenAI Gymを使った強化学習のためのライブラリです
table-baselinesでは、Q学習やSARSA、強化学習に基づく強化学習アルゴリズムを実装しており、簡単に強化学習を実装することができます。 - TensorFlow-Agents:Googleが提供する、TensorFlowを使った強化学習のためのライブラリ
TensorFlow-Agentsでは、深層学習を使った強化学習アルゴリズムを実装しており、高度な強化学習タスクを実現することができます。
機械学習とAIの関係性
 機械学習やAI、ディープラーニングなど、さまざまな単語を耳にするかと思います
機械学習やAI、ディープラーニングなど、さまざまな単語を耳にするかと思います
しかし、3者の違いがよくわからない、という方も少なくないと思います
ここからは、機械学習・AI・ディープラーニングの違いについて、解説を進めていきます
AIは人工知能でAIの中に機械学習は含まれている
機械学習はAIを構築するために必要な技術です
機械学習の教師あり学習や教師なし学習などで、正誤を学習しつつ、さまざまなグループに分けていきます
学習した結果、AIが最適な解を出力するようになります
機械学習とAIの違い
 AIはArtificial Intelligenceの略で、日本語では「人工知能」と呼ばれます
AIはArtificial Intelligenceの略で、日本語では「人工知能」と呼ばれます
一般社団法人人工知能学会では、AIを「知的なコンピュータプログラムを作る科学と技術」と定義しています
AIは人工知能と呼ばれていることから、人々が行っている知的活動をコンピュータで再現することを目的としています
人々が行っている知的学習を再現するためには、計算機科学上のモデルが必要になり、その一つが「機械学習」となります
機械学習とディープラーニングの違い
 ディープラーニングは機械学習によって構成されていますが、機械学習の発展型というイメージです
ディープラーニングは機械学習によって構成されていますが、機械学習の発展型というイメージです
行っていること自体は似ていますが、性能には明らかな違いがあります
機械学習の場合、予測精度を向上させるためには、人が何かしらの指示を入力する必要があります
しかし、ディープラーニングの場合、アルゴリズム自身がニューラルネットワークを使用して、予測が正しいかを判断します
ディープラーニングは、自分で自分が持っている機能を使って学習していくため、実際の脳を持っているかのように見えます
ニューラルネットワークについて
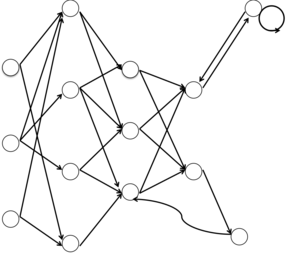 wikipediaより引用
wikipediaより引用
ニューラルネットワークは、人の脳の神経回路の一部を数理モデルもしくはパーセプトロンを複数組み合わせたものの総称です
ニューラルネットワークを活用したAI技術は、1957年にすでに開発されていました
しかし、インターネットやIT技術が発展しておらず、下火となってしまいました
その後、オートエンコーダーという技術や多層ニューラルネットワークなどの発展により、現在のAIブームを迎えています
Pythonが機械学習に使われる理由
 機械学習やAI、ディープラーニングの違いがわかったかと思います
機械学習やAI、ディープラーニングの違いがわかったかと思います
ここからは、機械学習にプログラミング言語のPythonが活用されてい理由について解説をしていきたいと思います
すでにPythonで機械学習が活用されている
 Pythonが注目を浴びるようになったきっかけは、機械学習の開発言語がPythonだったからでした
Pythonが注目を浴びるようになったきっかけは、機械学習の開発言語がPythonだったからでした
現在、多くの企業の業務ソフトやシステムに搭載されている開発言語は、その多くがPythonになっています
Pythonの機械学習を活用している例として、YouTubeやInstagramなどがあり、すでに導入している大企業があるため、今後もPythonの機械学習は活用されていくと言えます
コードがシンプル
 そもそもPython自体のコード記述がシンプルであるため、膨大なデータを処理する機械学習でも、コードをわかりやすく記述することができます
そもそもPython自体のコード記述がシンプルであるため、膨大なデータを処理する機械学習でも、コードをわかりやすく記述することができます
そのため、膨大なデータを処理するのにPythonは向いており、機械学習にPythonが使えわれている理由でもあります
豊富な機械学習ライブラリ
 また、Pythonは長年機械学習に使われてきているので、ライブラリが豊富に用意されています
また、Pythonは長年機械学習に使われてきているので、ライブラリが豊富に用意されています
ライブラリを活用することで、機械学習の効率化を図ったり、コードエラーを減少させることができます
公式ドキュメントなどの学習コンテンツが多い
 Pythonの機械学習に活用できるライブラリの他にも、公式ドキュメントやQiita、ZenなどのWebサイト、参考書などPythonで機械学習を学ぶ上で参考にすることができる学習コンテンツが多いのも、Pythonが機械学習に使われている理由です
Pythonの機械学習に活用できるライブラリの他にも、公式ドキュメントやQiita、ZenなどのWebサイト、参考書などPythonで機械学習を学ぶ上で参考にすることができる学習コンテンツが多いのも、Pythonが機械学習に使われている理由です
機械学習の実用例
 ここからは実際に機械学習の実用例について紹介していきます
ここからは実際に機械学習の実用例について紹介していきます
実用例を把握することで、どう言ったものをPythonの機械学習でプログラミングできるのか、イメージをつけることができます
画像解析
 機械学習でできることの1つに、画像解析があります
機械学習でできることの1つに、画像解析があります
画像解析の活用例では、モザイクのかかっている写真から元の写真を再現することができます
また、画像内に特定の物体が存在しているかどうかなどの解析にも活用することができます
画像認識は、自動運転、医療画像診断、画像検索など、多様な分野で利用されており、重要な役割を果たしています
音声認識
 音声認識は、音声からテキストへ変換を行うシステムです
音声認識は、音声からテキストへ変換を行うシステムです
音声認識には、教師あり学習アルゴリズムや、教師なし学習アルゴリズムが使われています
教師あり学習アルゴリズムでは、音声と対応するテキストのトレーニングデータを用いて、音声認識のモデルを学習させます
このモデルでは、新しい音声からテキストを予測することが可能です
教師なし学習アルゴリズムでは、トレーニングデータから音声の特徴を自動的に抽出し、音声認識のモデルを学習します
音声認識は、人工知能や機械学習の一分野として多くの研究が行われており、近年では自然な音声認識が実現されるようになってきています
テキスト分類
 テキスト分類は、テキストデータをカテゴリーに分類するシステムで、文書分類、評判分析、スパムフィルタリングなどの分野で使われています
テキスト分類は、テキストデータをカテゴリーに分類するシステムで、文書分類、評判分析、スパムフィルタリングなどの分野で使われています
テキスト分類は、主に教師あり学習のアルゴリズムが使われています
テキスト分類では、トレーニングデータとして、テキストと対応するカテゴリーが既知のデータが用意されます
このトレーニングデータを用いて、分類モデルを学習させていきます
この学習済みモデルは、新しいテキストデータを入力として、対応するカテゴリーを予測することができます
テキスト分類には、言語処理技術、機械学習アルゴリズム、深層学習アルゴリズム などが組み合わされます
自然言語処理
 自然言語処理は、人間が使用する自然言語 をコンピュータに処理するための技術です
自然言語処理は、人間が使用する自然言語 をコンピュータに処理するための技術です
自然言語処理には、文書のトピック分類、文書の要約、文書の評判分析、対話システム、翻訳などが含まれます
自然言語処理には、文書の単語や句読点などの分割、文書の正規化、文書の特徴量抽出、文書の類似度計算、深層学習アルゴリズム などが組み合わされます
推薦システム
 推薦システムは、ユーザーに対して適切な商品や音楽などを推薦するためのシステムです
推薦システムは、ユーザーに対して適切な商品や音楽などを推薦するためのシステムです
推薦システムは、ユーザーのクリック履歴や購買履歴などの行動データを分析し、ユーザーの興味に合ったアイテムを推薦することができます。
推薦システムは、教師なし学習、教師あり学習、協調フィルタリングアルゴリズムを使って実装されます
協調フィルタリングは、ユーザー同士の類似性を計算し、類似したユーザーが評価したアイテムを推薦することができます
協調フィルタリングには、User-Based Filtering、Item-Based Filtering、Matrix Factorizationなどがあります
推薦システムは、大量のユーザー行動データを処理するために、分散型システム やグラフ計算を用いることがあります
また、深層学習アルゴリズムを用いた推薦モデルも提案されています
アンサンブル学習
 アンサンブル学習は、複数のモデルを組み合わせて、より正確な予測を行う方法です
アンサンブル学習は、複数のモデルを組み合わせて、より正確な予測を行う方法です
アンサンブル学習には、バギング、ブースティング、スタッキングなどがあります
例えば、バギングは、トレーニングデータを複数のサブセットに分割し、各サブセットに対して同じアルゴリズムを使用して学習を行います
このとき、各モデルは独立して学習を行い、最終的な予測は各モデルの予測の結果を平均するなどの手法で統合されます
Pythonでは、scikit-learnライブラリを使用することで、アンサンブル学習を実装することができます
例えば、ランダムフォレストを使用する際には、RandomForestClassifier クラスを使用します
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
# トレーニングデータの生成
X, y = make_classification(n_samples=1000, n_features=4,
n_informative=2, n_redundant=0,
random_state=0, shuffle=False)
# ランダムフォレストモデルのインスタンス生成
clf = RandomForestClassifier(n_estimators=100, max_depth=2,
random_state=0)
# トレーニングデータを使用してモデルを学習
clf.fit(X, y)
# 予測
y_pred = clf.predict(X)
Pythonの代表的な機械学習ライブラリ
 ここからは、Pythonの代表的な機械学習ライブラリを紹介していきます
ここからは、Pythonの代表的な機械学習ライブラリを紹介していきます
いくつかサンプルコードも紹介していきますので、ぜひ参考にしてみてください
TensorFlow
 TensorFlowは機械学習やディープラーニングを行うためのライブラリです
TensorFlowは機械学習やディープラーニングを行うためのライブラリです
TensorFlowでは、パターン認識やデータ分類、将来予測などを行うことができます
TensorFlowはTwitterの関連ツイートをタイムラインの上部に表示させる技術に活用されています
scikit-learn
 scikit-learnは機械学習を行う際の、基本的なライブラリになるので、機械学習を始める際には、scikit-learnの習得をまずは目指します
scikit-learnは機械学習を行う際の、基本的なライブラリになるので、機械学習を始める際には、scikit-learnの習得をまずは目指します
scikit-learnでは、教師あり学習・教師なし学習に関するアルゴリズムを一通り実装することができます
scikit-learnでできることは、
- 回帰
- 分類
- クラスタリング
- 次元削減
- データの前処理
- モデル評価と選択
などです
また、scikit-learnの公式サイトには、どういったサンプルデータがあるかが掲載されています
サンプルデータを使って、機械学習を行いたい方は、参考にしてみてください
OpenCV
 OpenCVは画像認識ライブラリで、画像に写っている顔の認識を行うことができます
OpenCVは画像認識ライブラリで、画像に写っている顔の認識を行うことができます
企業の顔認証セキュリティなどに活用されています
OpenCVとTensorFlowやPyTorchなどを組み合わせて実装することで、実現することができます
Numpy
 Numpyは数値計算ライブラリで、多次元配列を扱うことができます
Numpyは数値計算ライブラリで、多次元配列を扱うことができます
多次元配列は数学の行列のことを指しており、機械学習では行列が基本の概念となります
そのため、Pythonの機械学習のライブラリは、その多くがnumpyを使用しています
また、機械学習を行う際の、データ前処理でもnumpyは活躍するため、numpyの理解を深めることは大切になります

Keras
 Kerasは、Pythonで書かれたオープンソースのライブラリで、ニューラルネットワークを簡単に構築・学習・評価することができます
Kerasは、Pythonで書かれたオープンソースのライブラリで、ニューラルネットワークを簡単に構築・学習・評価することができます
Kerasは、TensorFlowなどのバックエンドを使用しているため、TensorFlowなどを組み合わせることで高度な機能を使うことができます
以下は、Kerasを使ってニューラルネットワークを構築し学習する際に参考になるステップです。
- Kerasをインストールする:
pip install keras - Kerasをインポートする:
import keras - 入力データと出力データを定義する
- モデルを構築する: Kerasではモデルをレイヤーオブジェクトで構築
- コンパイルし学習させる: モデルに学習アルゴリズム、損失関数、評価関数を選択し、学習データを用いてパラメータを調整
- モデルを評価する: テストデータを用いて性能を評価
- モデルを使用する: 学習済みモデルを使って新しいデータに対する予測を行います
Kerasは、簡単なAPIで構築ができるため、初心者にもおすすめのライブラリです
また、Kerasには多くのアーキテクチャのネットワークが実装されているので、それを組み合わせることで高度なモデルを構築することができます
PyTorch
 PyTorchは、Facebookが開発したディープラーニング向けフレームワークです
PyTorchは、Facebookが開発したディープラーニング向けフレームワークです
PyTorchでは、柔軟なニューラルネットワークの記述が可能で、ディープラーニングの中でも人気があります
PyTorch自体はNumpyに操作方法が似ているため、Numpyを使用したことがある方であれば、スムーズに利用することができます
また、PyTorchの情報は豊富にあり、書籍もあるため、必要な情報を必要なタイミングで入手しやすいAIライブラリです

seaborn
seabornを使うことで、以下のような可視化を行うことができます
seabornはデータを可視化するためのライブラリです
seabornでは、美しく情報豊富なグラフを作成することができます
seabornはMatplotlibの上に構築されており、多くの種類のプロットを作成するためのより便利なAPIを提供しています
matplotlib
 matplotlibはPythonで使用されるグラフ描画ライブラリで、画像のようなグラフを作成することができます
matplotlibはPythonで使用されるグラフ描画ライブラリで、画像のようなグラフを作成することができます
数値解析やデータ可視化などに利用されます
matplotlibは非常に高機能で、簡単なグラフから複雑な3次元グラフまで作成することができますが、より美しい可視化を目指す場合には、seabornの利用がおすすめです
Pythonで機械学習を行う流れ
 ここからはPythonで機械学習を行う流れについて解説をしていきます
ここからはPythonで機械学習を行う流れについて解説をしていきます
いきなり機械学習の完成を目指すのではなく、一つ一つ細分化して実装していくことで、機械学習が完成していきます
- データの準備
- データの前処理
- モデルの選択
- モデルの学習
- モデルの評価・改善
データ準備
 機会学習に使用するデータを準備します
機会学習に使用するデータを準備します
このデータは、学習させることを目的とする入力と入力の答えのペアで構成されます
Pythonのライブラリには、サンプルのデータセットが用意されていることが多いので、そういったものを使用して、機械学習を実装していくとデータ準備を行う手間が省けます
データ前処理
 データを加工し、モデルの学習に適した形式に整えます
データを加工し、モデルの学習に適した形式に整えます
データを訓練用データセットとテスト用データセットに分割することもあります
モデル選択
 どのようなモデルを使用したら、最も学習効果が高いかを考え、モデルを組み立てていきます
どのようなモデルを使用したら、最も学習効果が高いかを考え、モデルを組み立てていきます
機械学習のモデルの代表的なものには、
- ニューラルネットワーク
- サポートベクターマシン
- ランダムフォレスト
- ナイーブベイズ
- 主成分分析
- 線形回帰
- ロジスティック回帰
などがあります
モデルの学習
 モデルを訓練用データセットで学習させます
モデルを訓練用データセットで学習させます
学習には、モデルのパラメータを最適化するためのアルゴリズムが必要となります
モデルの評価・改善
 学習したモデルをテスト用データセットで評価します
学習したモデルをテスト用データセットで評価します
機械学習モデルの評価方法として、データセットを訓練用データセット、評価用データセット、テスト用データセットに分割する方法や評価指標を用いてモデルの性能を評価する方法、特徴量の増減や2乗項や交互作用項などを調整してモデルの正規化を行うなどがあります
また、モデルの評価結果から、モデルの改善を行います
例えば、予測精度が低い場合は、モデルの複雑さやデータの正規化などを行って、性能を向上させることができます
Pythonで機械学習のプログラミングを学ぶコツ
 Pythonで機械学習のプログラミングを学ぶコツとして、実装したいものをあらかじめ決めておく、ということが挙げられます
Pythonで機械学習のプログラミングを学ぶコツとして、実装したいものをあらかじめ決めておく、ということが挙げられます
実装したいものがない場合には、仮想通貨や株価の予測をPythonの機械学習で実装していくのが、わかりやすいかと思います
独学で学ぶ場合
 独学で学ぶ場合には、実装したいものがないと難しいと思います
独学で学ぶ場合には、実装したいものがないと難しいと思います
実装したいものがない場合には、サンプルコードの写経から進めて、一つずつ理解していくのがいいですね
僕も実装したいものがないけど、学びたいものがある、という場合には写経を行なっています
仮想通貨bitcoinの価格を予想するサンプルコードは、次のようになります
このコードはJupyter Notebookで実装しています
ライブラリのインストールなどが終わっていれば、Jupyter Notebookならコピペでいけると思います
import pandas as pd
import yfinance
import matplotlib.pyplot as plt
from prophet import Prophet
from prophet.plot import plot_plotly
import plotly.offline as py
from prophet.diagnostics import cross_validation
from prophet.diagnostics import performance_metrics
from prophet.plot import plot_cross_validation_metric
# ビットコイン価格の時系列データ
symbol = "BTC-JPY" # 通貨コード
period = "max" # 期間
# データ取得
Ticker = yfinance.Ticker(symbol)
data = Ticker.history(period=period)
#print(data)
#ビットコインのヒストリカルデータの可視化
plt.plot_date(data.index, data["Close"], linestyle='solid')
# 書式設定
plt.xlabel("Date")
plt.ylabel("Bitcoin")
plt.legend(loc="best") # 凡例
plt.gcf().autofmt_xdate() # X軸値を45度回転
#plt.show() # グラフ表示
# Prophet投入用インプットデータ作成
df = pd.DataFrame({"ds":data.index, "y":data["Close"]}).reset_index(drop=True)
#print(df)
# モデルインスタンス
proph = Prophet()
# モデル学習
proph.fit(df)
# 未来予測用のデータフレーム
future = proph.make_future_dataframe(periods=365)
# 時系列を予測
forecast = proph.predict(future)
# 出力
#print(forecast)
py.init_notebook_mode()
figure = plot_plotly(proph, # 時系列モデル
forecast, # 予測結果
)
# 出力
#py.iplot(figure)
# 予測性能評価用のデータ準備
df_cv = cross_validation(proph, initial='730 days', period='180 days', horizon = '365 days')
# 出力
print(df_cv)
plt.show()
# 回帰モデルの評価指標獲得
df_performance = performance_metrics(df_cv)
# 出力
print(df_performance)
# 評価結果を可視化
figure = plot_cross_validation_metric(df_cv, metric='rmse')プログラミングスクールの利用
 Pythonの独学は挫折をしやすいです
Pythonの独学は挫折をしやすいです
特に学び始めた初期は、エラーが頻発し、エラーを解消することができず、嫌になってしまいます
そうなってしまわないように、プログラミングスクールを利用するのも、Pythonで機械学習のプログラミングを行うコツです
最近はプログラミングスクールがたくさん出てきていますが、データ分析や機械学習をPythonで学ぶとしたら、キカガクがおすすめです
キカガクは、初心者からAIエンジニアに転職可能なプログラミングスクールで、最新技術を学ぶことができます
無料個別相談会をオンラインで行っているので、興味がある方は一度参加してみるのをおすすめします
※無料オンライン相談や個別相談などさまざまなイベントが開催中
まとめ
 Pythonで機械学習のプログラミングを学ぶには、実装したいものを決めておくのが一番早いと思います
Pythonで機械学習のプログラミングを学ぶには、実装したいものを決めておくのが一番早いと思います
しかし、実装したいものがないという場合には、サンプルコードの写経やプログラミングスクールの利用をおすすめします
機械学習の場合、開発したいものが簡単には思い浮かばないと思いますので、まずはサンプルコードを使って、イメージを掴むのが大切だと思います









