
この記事では、Pythonで機械学習のクラスタリングを実装していきます
クラスタリングは機械学習の中でも教師なし学習に分類される、機械学習です
PythonではK-meansを使ったクラスタリングを簡単に実装することができるので、一緒に実装していきましょう
筆者について
2021年から本格的にPython学習を始め、今ではPythonによる収益化に成功
大学院時代には、R言語とPythonを使って統計処理を行っていたため、Pythonを使ったデータサイエンスの知識が豊富
医療データを機械学習を用いて解析したり、学会発表も行なっている
機械学習やAIでは、データサイエンスが非常に重要になります
データサイエンスについて学びたい場合には、データミックスの利用がおすすめです
データミックスは、データサイエンスに特化したプログラミングスクールで、データサイエンスを学びながら、pythonを学ぶことができます
無料個別相談会をオンラインで行っているので、興味がある方は一度参加してみるのをおすすめします
※無料オンライン相談や個別相談などさまざまなイベントが開催中
Contents
クラスタリングは類似度でデータをグループ分けする

機械学習で使われるクラスタリングは、データの類似度によって、データをグループ分けする方法になります
例えば、企業の広告メールで考えてみます
若者向けの新商品ができた場合、過去に商品を購入してくれた顧客100名に対して、全く同じ内容のメールを送信すれば、労力は少なくて済みますが、新商品が売れるかどうかわかりません
若者向けの既存商品を購入してくれたことがある顧客のみにメールを送れば、費用を抑えることが出来ますし、購入確率も上がります
過去に購入した商品は、年代別や類似した商品の購入など、さまざまなパターンがありますが、このようなパターンを見つけ出し、グループ分けを行なっていくのが、クラスタリングになります
クラスタリングは、マーケティングやレコメンドエンジンのアルゴリズムなどに活用されています
クラスタリングは機械学習の教師なし学習に分類される
機械学習には、教師なし学習・教師あり学習・強化学習があります
教師あり学習とは、事前に与えられた情報をもとに、学習を行なっていく手法です
教師なし学習とは、事前に情報を与えられることなく、手元のデータをグループ分けしていくことになります
また、強化学習というのは、ある特定の行動(や動作)を取った際に報酬(評価)が与えられ、最も多く報酬を得られるように試行錯誤しながら、学習していく手法です
教師あり学習は、分類や回帰に利用されるケースが多く、教師なし学習は、グループ分けや情報の要約などに利用されます
強化学習の例として、アルファ碁というものがあります
>>>「囲碁AI」の最強時代到来、プロ棋士の存在価値は薄れてしまうのか?
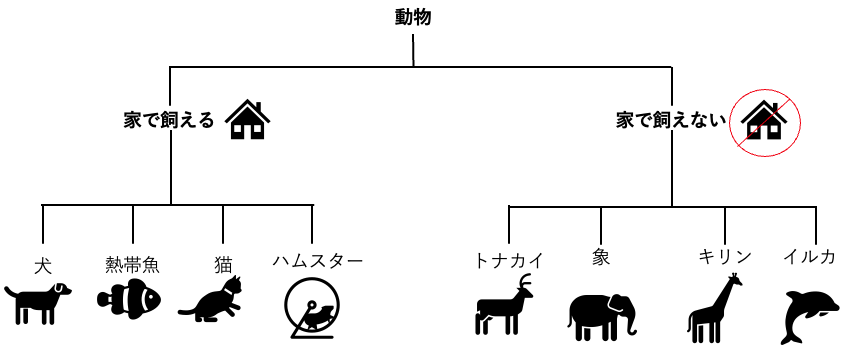
階層的クラスタリング
クラスタリングには、階層的クラスタリングと非階層的クラスタリングがあります
- hierarchical clustering:階層的クラスタリング
- K-means:k平均法(非階層的クラスタリング)
階層的クラスタリングでは、最も似ている(似ていない)データ同士を一つずつグループに分けていき、複数の階層を作っていく手法になります
全てのグループ分けが終了すると、デンドログラムと呼ばれる図が作られます
非階層的クラスタリング
一方で、K-means(非階層的クラスタリング)は、階層は作らずにあらかじめ定めておいたグループ数になるように、類似度の高いデータを集めていきます
非階層的クラスタリングは、グループ数をあらかじめ決めておくことができるため、ランダムで大量データを分析する際に向いています
非階層的クラスタリングの種類
非階層的クラスタリングは、k-meansのほかに、
- Forgy法
- Jancey法
があります
また、k-meansは、
- MacQueen’s k-means法
- convergent k-means法
の二つに分けられます
クラスタリングについて、詳しく知りたい方は、以下の書籍で学ぶことができます

k-meansとは
k-meansとは、k(個)のクラスタに分類するのに、平均(mean)を使って分類しよう、という手法になります
クラスタというのは、データの集合体を指しています
また、グループ分けされた各グループの意味付けは、自身で行う必要があります
Pythonで機械学習のクラスタリングを実装する

では、実際にここからはPythonで機械学習のクラスタリングを実装していきたいと思います
クラスタリングを行う前に、いくつか準備があります
- データの準備
- 欠損値処理
- 文字列を数値に変換する(ダミー変数処理)
- データを標準化する
- データを可視化する
大まかに、上記の流れでクラスタリングは行われていきます
今回は、もともと用意されているデータを使用するので、欠損値処理などは割愛します
欠損値処理などの前処理は、以前の記事でも解説しているので、そちらも参考にしてみてください
クラスタリングで使うデータの準備
今回、クラスタリングで使うデータはscikit-learnの公式ドキュメントで提供されているデータを使用します
# datasetの読み込み
wine_data = datasets.load_wine()
# DataFrameに変換
df = pd.DataFrame(wine_data.data, columns=wine_data.feature_names)
print(df.head())
>>>出力結果
alcohol malic_acid ash alcalinity_of_ash magnesium total_phenols flavanoids nonflavanoid_phenols proanthocyanins color_intensity hue od280/od315_of_diluted_wines proline
0 14.23 1.71 2.43 15.6 127.0 2.80 3.06 0.28 2.29 5.64 1.04 3.92 1065.0
1 13.20 1.78 2.14 11.2 100.0 2.65 2.76 0.26 1.28 4.38 1.05 3.40 1050.0
2 13.16 2.36 2.67 18.6 101.0 2.80 3.24 0.30 2.81 5.68 1.03 3.17 1185.0
3 14.37 1.95 2.50 16.8 113.0 3.85 3.49 0.24 2.18 7.80 0.86 3.45 1480.0
4 13.24 2.59 2.87 21.0 118.0 2.80 2.69 0.39 1.82 4.32 1.04 2.93 735.0欠損値処理やダミー変数処理は今回必要ありません
今回使用するのは、読み込んだデータセットのうち、”alcohol”,”color_intensity”を使用していきます
クラスタリングは2次元の配列を使って、実装していくものなので、2つ選んでおきます
データを標準化する
読み込んだデータフレームを標準化していきます
標準化には、scikit-learnのStandardScalerを使用します
sc = preprocessing.StandardScaler()
sc.fit(X)
X_norm = sc.transform(X)クラスタリングを実装する
最後にクラスタリングを実装します
# クラスタリング
cls = KMeans(n_clusters=3)
result = cls.fit(X_norm)n_clusterというのは、クラスタ数をいくつにするかを指定します
今回は3つで指定をしています
クラスタ数を決める手法
クラスタ数は事前に定めておかないと、クラスタリングを行うことが出来ません
クラスタ数を決める手法には、
- エルボー法
- シルエット法
がありますが、エルボー法が簡単なので、エルボー法を実装します
distortions = []
for i in range(1,11): # 1~10クラスタまで一気に計算
km = KMeans(n_clusters=i,
init='k-means++', # k-means++法によりクラスタ中心を選択
n_init=10,
max_iter=300,
random_state=0)
km.fit(X) # クラスタリングの計算を実行
distortions.append(km.inertia_) # km.fitするとkm.inertia_が得られる
plt.plot(range(1,11),distortions,marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Distortion')
plt.show()エルボー法では、クラスタごとのSSE値をプロットし、肘のように曲がった点が最適なクラスタ数とみなすとされています
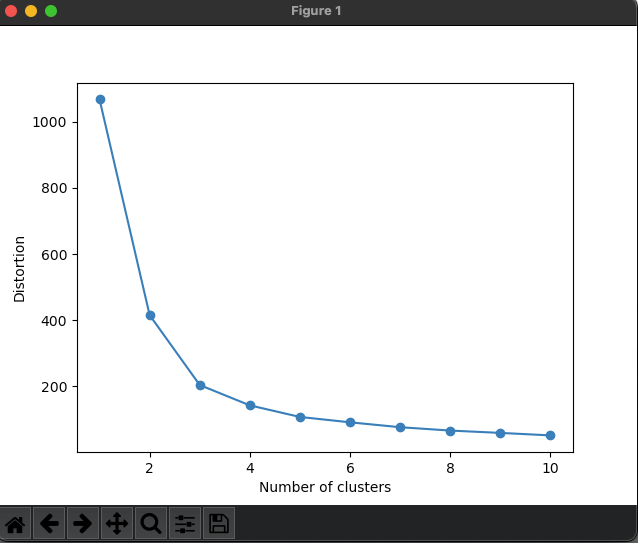
今回の場合、急激に曲がるのが、3の地点なので、クラスタ数は3が最適であることがわかります
クラスタリングを可視化する
クラスタリングを実装したら、可視化も行なっていきます
可視化にはmatplotlibを使用していきます
# 結果を出力
plt.scatter(X_norm[:,0],X_norm[:,1], c=result.labels_)
plt.show()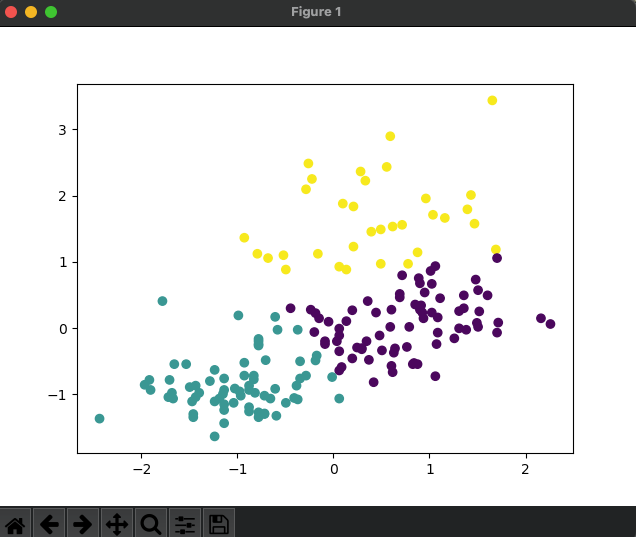
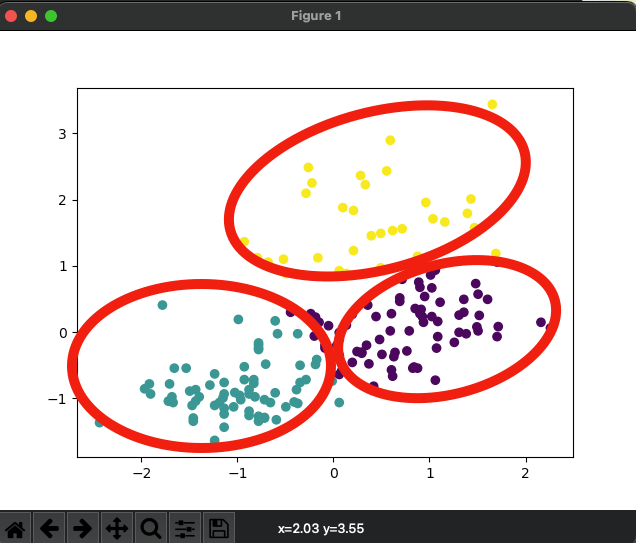
実際にクラスタリングを行ってみると、赤丸のようにグループ分けされているのがわかります
Pythonで機械学習をより学びたい場合
 Pythonで機械学習をより学びたい場合には、プログラミングスクールに通うのがおすすめです
Pythonで機械学習をより学びたい場合には、プログラミングスクールに通うのがおすすめです
Pythonは独学で学ぶことができるプログラミング言語ですが、独学では時間がかかってしまうのと体系的に学ぶことが出来ません
自分の興味・関心のある部分を、つまみながら学習するため、Pythonの本質を理解するまでにも時間がかかってしまいます
そのため、費用はかかってしまいますが、プログラミングスクールの活用がベストです
スクールに通いながら、受けられそうな案件を受けることで、スクール代を回収することもできるので、ぜひチャレンジしてみてください
プログラミングスクールに通うことで、漏れなく体系的にPythonや機械学習について学ぶことができます
.Pro
.Proでは「Python」のカリキュラムを4年前に作成して以来、常にアップデートを行っており、近年では業務効率化にも幅を広げています
人工知能やwebサービス・機械学習を学ぶ、プログラミング特化コースです。
.Proがおすすめなのは、
- プログラミング未経験だけど新しく挑戦したい
- 人とコミュニケーションをとるのが苦ではない
- すぐにでも転職できる実践型スキルを本気で身につけたい
といった人たちです
特に、.Proを受講する方の約9割はプログラミング未経験の方なので、初めてプログラミングに触れる、といった方でも安心して受講することが出来ます。
.Proの受講期間は6ヶ月と長期であるため、途中で挫折しないためにも、雰囲気を味わっておくことは重要です
.Proでは実際の授業の雰囲気も見ることができ、講義開催日である土曜日に対面での個別相談も開催されています。
Aidemy Premium
Aidemy Premiumは、オンラインで学べるプログラミングスクールです。Aidemyでは、初心者から上級者まで、様々なプログラミング言語を学ぶことができます。
Aidemyでは、以下のようなプログラミング言語を学ぶことができます。
- HTML/CSS
- JavaScript
- Python
- Ruby
- PHP
- Java
Aidemy Premiumでは、ビデオ講義や実践問題を通じて、ハンズオンで学ぶことができます。
また、学習を支援するために、専任のキャリアカウンセラーがいるほか、学習をサポートするSlackコミュニティも用意されています。
Aidemy Premiumでは、さまざまなプランが用意されており、月額料金や有効期限が異なります。
| アイデミー(Aidemy Premium)の主なコース | 習得できるスキル |
|---|---|
| AIアプリ開発コース | Python/HTML・CSS/Git/Flask(PythonのWEBアプリフレームワーク)/機械学習/WEBスクレイピング |
| データ分析コース | Python/Pandas/Numpy/機械学習(教師あり・教師なし)/データクレンジング/時系列解析/ディープラーニング |
| 自然言語処理コース | Python/Pandas/Matplotlib/機械学習(教師あり・教師なし)/自然言語処理/ディープラーニング |
| ビジネスAI活用講座 | DX入門/AIマーケター育成コース/Python/Numpy/機械学習/AIリテラシー/ビジネスへのAI活用 |
| 運営元 | 株式会社アイデミー |
| 本社 | 東京都千代田区神田小川町一丁目1番地 山甚ビル3F |
| 料金 | プレミアムプラン 3ヶ月/327,800円(税込)〜 |
| 学習内容 | Python基礎・データ操作・アルゴリズムなど |
| 受講形式 | オンライン |
そのほかのPythonが学べるおすすめのプログラミングスクールは、こちらの記事で詳しく解説しているので、参考にしてみてください
>>>pythonを学ぶのにおすすめプログラミングスクールTOP5
Pythonで機械学習のクラスタリングを実装する まとめ

機械学習の一つである、クラスタリングは難しそうなイメージがありますが、Pythonを使うことで簡単に実装することができます
マーケティングなどにも活用することができるので、ぜひPythonでクラスタリングを実装してみてください
機械学習やAIでは、データサイエンスが非常に重要になります
データサイエンスについて学びたい場合には、データミックスの利用がおすすめです
データミックスは、データサイエンスに特化したプログラミングスクールで、データサイエンスを学びながら、pythonを学ぶことができます
無料個別相談会をオンラインで行っているので、興味がある方は一度参加してみるのをおすすめします
※無料オンライン相談や個別相談などさまざまなイベントが開催中








