
Pythonでデータ分析から可視化までを簡単に行う方法を知りたい
Pythonでデータ分析を行なった後に、どのような可視化ができるかを知りたい
こんな疑問にお答えします
実際にはこのような可視化ができるようになります
可視化について理解ができたら、実際にデータ分析・機械学習を実装していきましょう
Pythonでデータ分析を始めよう!挫折しない実践ガイドでスキルアップ
Pythonで機械学習に学んで実装してみよう【サンプルコードあり】
pythonでデータ分析から可視化を行う方法
可視化を行うためには、まずはpythonでデータ分析を行う必要があります
Pythonでデータ分析を行うならば、以下のライブラリがおすすめです
- pandas
- numpy
- scikit-learn
特にpandasとnumpyはcsvファイルを読み込むことができるので、データ分析を行いやすいライブラリと言えます
Pandasとnumpyでcsvファイルを読み込む方法は以下の記事を参考にしてください
scikit-learnは機械学習ライブラリであり、分類や回帰分析、クラスタリング、主成分分析などを行うことができます
前処理や統計処理に関しては、以下の記事で詳細に解説をしているので、そちらを参考にしてください
本格的にpythonを使ってデータサイエンスを学びたいと考えている方は、データミックス![]() を活用して学ぶのもおすすめです
を活用して学ぶのもおすすめです
可視化を行うライブラリ
Pythonで可視化を行うには以下のようなライブラリを使用します
- matplotlib
- Bokeh
- Plotly
- HoloViews
- Pygal
- seaborn
などがあります
それぞれ様々な特徴がありますが、seabornはデフォルトでも綺麗な可視化を行うことができます
以下の記事では相関係数を求めてから、可視化までを解説しています

pythonで可視化を行う
ここからは実際に可視化を行なっていきたいと思います
今回はseabornに含まれている「iris」のデータをもとに作成していきたいと思います
seabornで可視化を行う
まずはseabornで可視化を行なっていきたいと思います
まずは「iris」のデータをインポートします
import pandas as pd
import seaborn as sns
sns.set()
iris=sns.load_dataset("iris")
print(iris)
>>>出力結果
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 virginica
146 6.3 2.5 5.0 1.9 virginica
147 6.5 3.0 5.2 2.0 virginica
148 6.2 3.4 5.4 2.3 virginica
149 5.9 3.0 5.1 1.8 virginica
[150 rows x 5 columns]pairplotを行う
mport pandas as pd
import seaborn as sns
sns.set()
iris=sns.load_dataset("iris")
print(iris)
#csvで読み込む場合
#file=pd.read_csv("XXXX.csv)
#irisのデータをseabornのpairplotで出力
sns.pairplot(iris)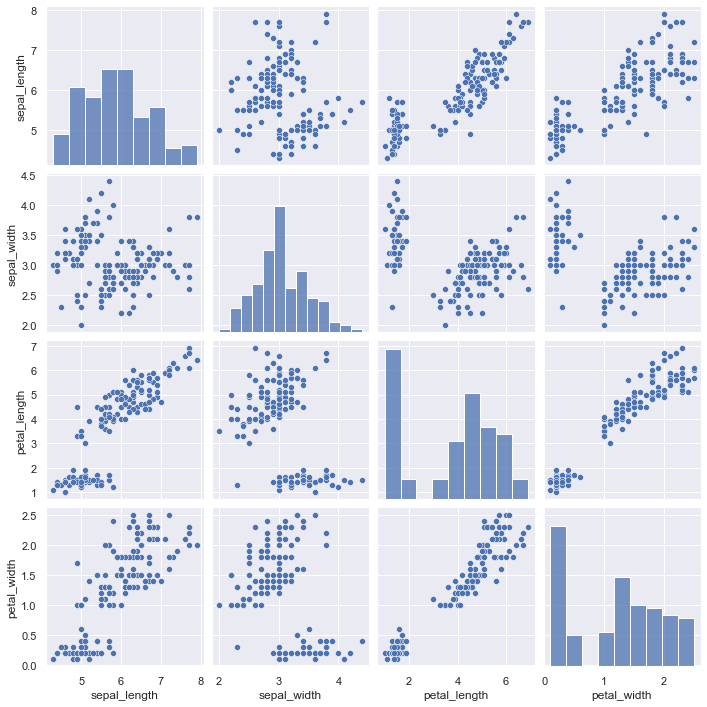
pairplotで色を変える
上記の可視化では、色が全て同じであるため、いまいちわかりにくい結果となっています
そこで、”hue”を指定します
import pandas as pd
import seaborn as sns
sns.set()
iris=sns.load_dataset("iris")
print(iris)
#csvで読み込む場合
#file=pd.read_csv("XXXX.csv)
#hueで指定して色分け."species"で色分けを指定
sns.pairplot(iris,hue="species")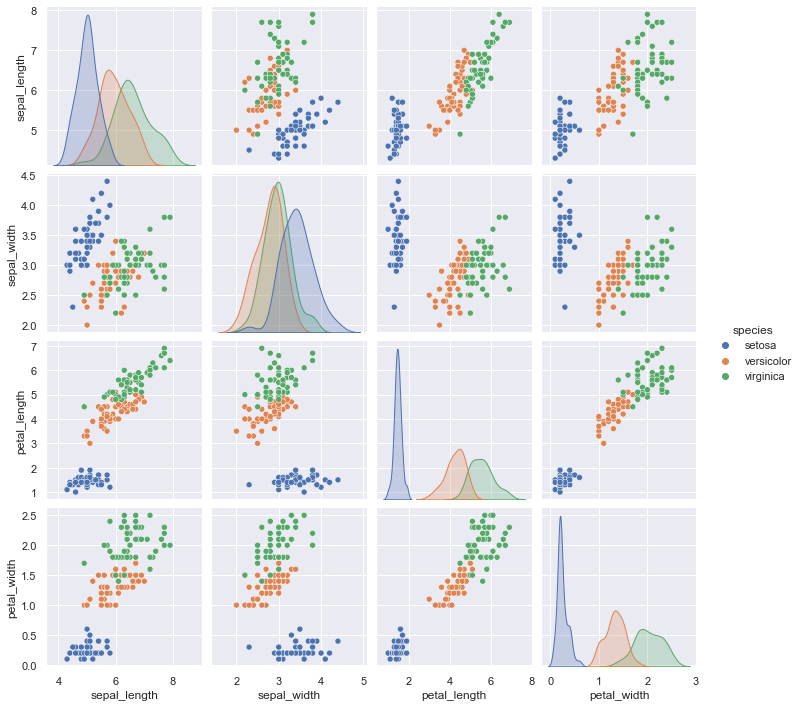
spciesは種類によって分類されており、irisに含まれるのは3種類です
そのため、3色で可視化がされました
pairplotでグラフ化する列を指定
varsもしくはx_vars,y_varsを指定すれば、グラフ化する列を指定することもできます
import pandas as pd
import seaborn as sns
sns.set()
iris=sns.load_dataset("iris")
#csvで読み込む場合
#file=pd.read_csv("XXXX.csv)
#sns.pairplot(iris)
#グラフ化する列を指定varsを使用
sns.pairplot(iris,hue="species",
vars=["sepal_length"])
#グラフ化する列は増やせる
sns.pairplot(iris,hue="species",
vars=["sepal_length","sepal_width"])
#グラフ化する列はx_varsとy_varsでも指定可能
#sns.pairplot(iris, hue='species',
x_vars=['sepal_length', 'sepal_width'],
y_vars=['petal_length', 'petal_width'])
pairplotでマーカーを変更する
import pandas as pd
import seaborn as sns
sns.set()
iris=sns.load_dataset("iris")
#csvで読み込む場合
#file=pd.read_csv("XXXX.csv)
#sns.pairplot(iris)
#マーカーの変更
sns.pairplot(iris, hue='species', markers='+')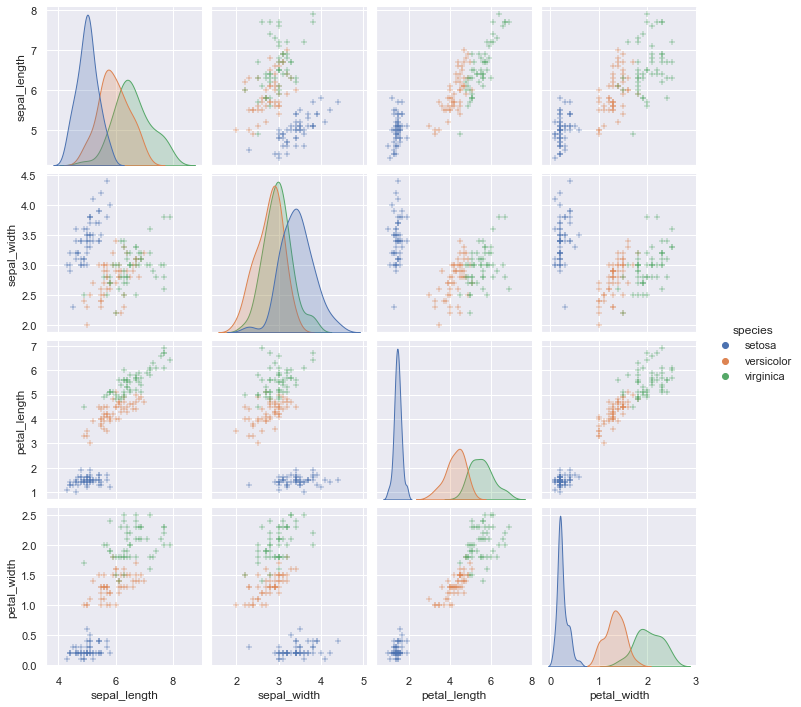
マーカーの種類はこちらから
pairplotで回帰直線をプロット
回帰直線をプロットする場合には、kind=”reg”と指定します
import pandas as pd
import seaborn as sns
sns.set()
iris=sns.load_dataset("iris")
#csvで読み込む場合
#file=pd.read_csv("XXXX.csv)
#sns.pairplot(iris)
#回帰直線をプロットkindを使用
sns.pairplot(iris, hue='species', kind='reg')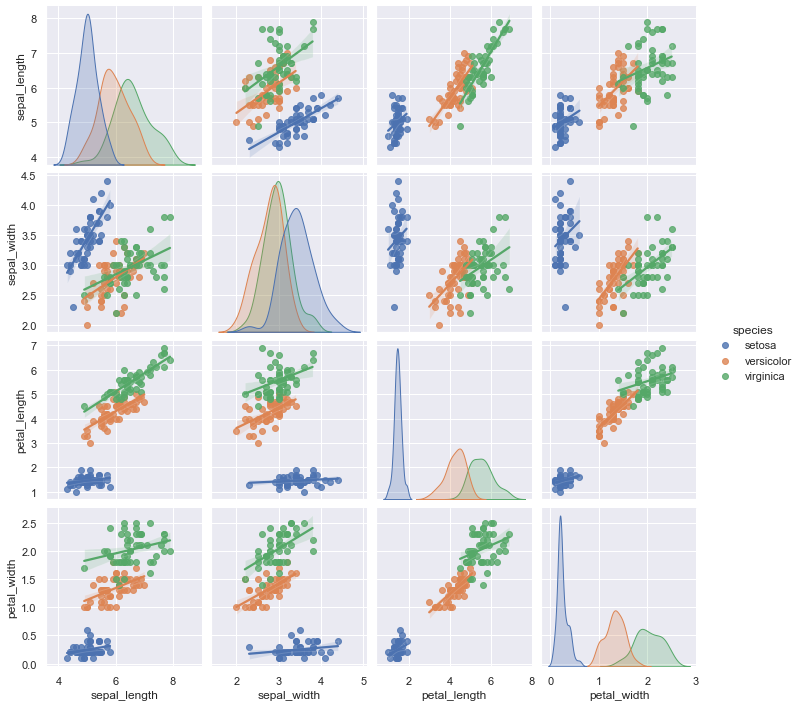
ヴァイオリンプロットを描く
import pandas as pd
import seaborn as sns
sns.set()
iris=sns.load_dataset("iris")
#csvで読み込む場合
#file=pd.read_csv("XXXX.csv)
#sns.pairplot(iris)
#ヴァイオリンプロット
sns.violinplot(x="species", y="sepal_length",data=iris)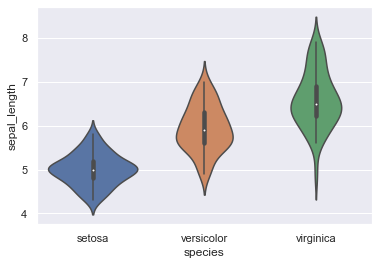
棒グラフを描く
import pandas as pd
import seaborn as sns
sns.set()
iris=sns.load_dataset("iris")
#csvで読み込む場合
#file=pd.read_csv("XXXX.csv)
#sns.pairplot(iris)
#棒グラフ
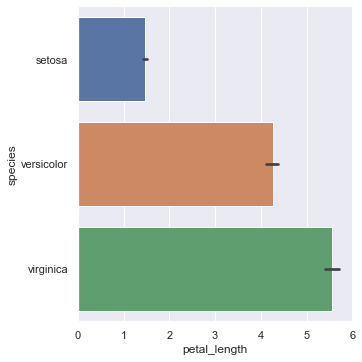
sns.catplot(x="petal_length",data=iris,kind="count")
#棒グラフにエラーバーをつける
sns.catplot(x="petal_length",y="species",data=iris,kind="bar")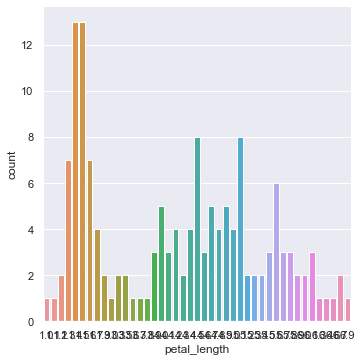
棒グラフのみでは平均値の比較ができないため、エラーバー付きに変えると平均値での比較をすることができます
ヒストグラムを描く
import pandas as pd
import seaborn as sns
sns.set()
iris=sns.load_dataset("iris")
#csvで読み込む場合
#file=pd.read_csv("XXXX.csv)
#sns.pairplot(iris)
#ヒストグラム
sns.distplot(iris["sepal_length"])
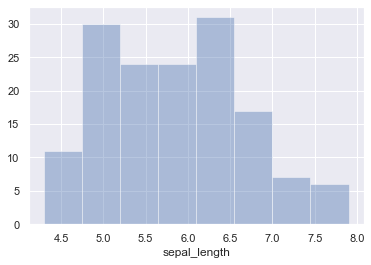
#確率密度関数を削除して、ヒストグラムだけを書く
sns.distplot(iris["sepal_length"],kde=False)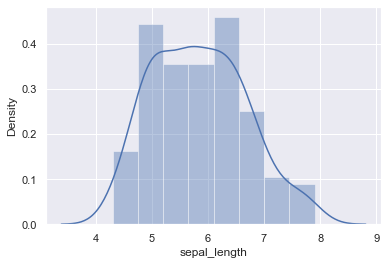
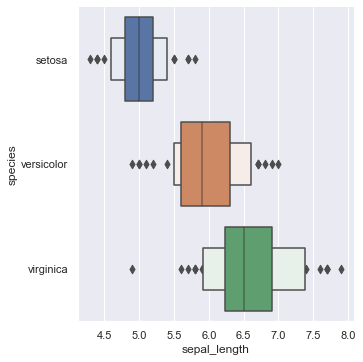
箱ひげ図を描く
import pandas as pd
import seaborn as sns
sns.set()
iris=sns.load_dataset("iris")
#csvで読み込む場合
#file=pd.read_csv("XXXX.csv)
#sns.pairplot(iris)
#箱ひげ図を書くkind="box"を使用
sns.catplot(x="sepal_length",y="species",data=iris,kind="box")
#kind="boxen"でより詳細な表示
sns.catplot(x="sepal_length",y="species",data=iris,kind="boxen")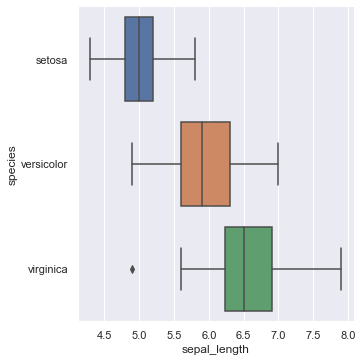
scatter plotを描く
import pandas as pd
import seaborn as sns
sns.set()
iris=sns.load_dataset("iris")
#csvで読み込む場合
#file=pd.read_csv("XXXX.csv)
#sns.pairplot(iris)
#scatter plotを描く
sns.catplot(x="sepal_length",y="species",data=iris)
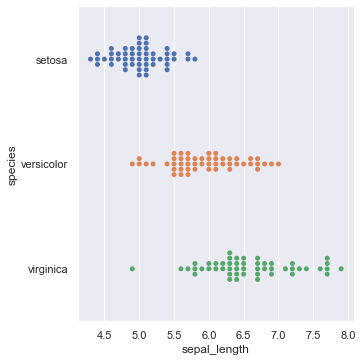
#scatter plotをより詳しく
sns.catplot(x="sepal_length",y="species",data=iris,kind="swarm")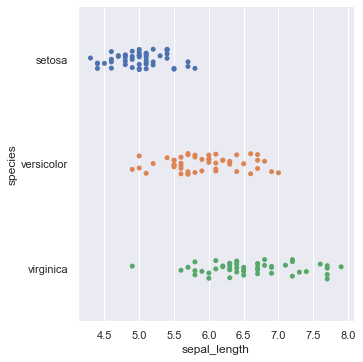
ここまでできたら、実際にデータ分析・機械学習を実装していきましょう
Pythonでデータ分析を始めよう!挫折しない実践ガイドでスキルアップ
Pythonで機械学習に学んで実装してみよう【サンプルコードあり】
まとめ
pythonでデータ分析などを行うときには、可視化は必須になります
また、データの前処理やデータの解釈などを行えることで、データ分析には必要となります
これからpythonを使ってデータサイエンスを学びたいと考えている方は、データミックス![]() を活用して学ぶのもおすすめです
を活用して学ぶのもおすすめです
国内においてデータサイエンティストの需要と供給が間に合っていないため、今のうちにデータサイエンスを学んでおけば、重宝される人材になれます
※無料オンライン相談や個別相談などさまざまなイベントが開催中












