pythonで分析や統計をしたいと思っているけど、いまいちよくわからない
Pythonで分析や統計を行う際にpandasでどういったことができるのか知りたい
こんな疑問にお答えします
Contents
pandasとは
pythonのライブラリの一種で、データ解析の機能を有しています
pandasは、プログラミング言語Pythonにおいて、データ解析を支援する機能を提供するライブラリである。
特に、数表および時系列データを操作するためのデータ構造と演算を提供する。
PandasはBSDライセンスのもとで提供されている。
wikipediaより
pandasを使用する場面としては、
- 統計処理
- 機械学習
- 深層学習
上記の処理を行う前段階に行うことがほとんどです
そのため、pandasなどを使用した処理などのことを「データの前処理」と呼びます
統計や機械学習などのモデルを決定するのは、データの質であるため、この前処理を適当に行ってしまうと、とんでもない結果につながる可能性があります
データの質は、データを適切に把握し、不要なデータを取り除いたり、必要なデータを精査する前処理を行うことで高めることができます
データ分析の約8割は前処理で決定される
とも言われているほど、前処理・データの質というものは重要になります
pandasの前処理について学ぶならこの書籍が一番です

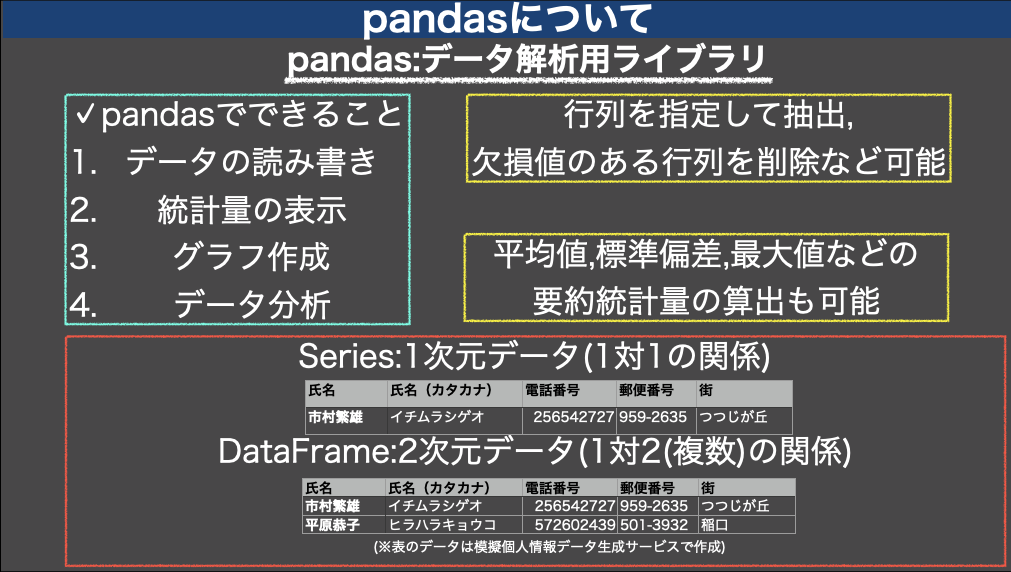
pandasで出来ること
pandasを使用することで以下のようなことが可能となります
- データの読み込みや統計量の表示
- グラフ化
- データ分析
さらに細かく分けると以下のようなことが可能です
データの読込
- CSV形式のデータの読込:read_csv()
- Excelファイルの読込:read_excel()
- JSON文字列の読込:read_json()
- pickle形式(Pythonオブジェクトを保存する形式)によるデータの読込/書込:read_pickle()、to_pickle()
- インターネット上で提供されている株価情報の読込:pandas-datareader
データの特徴を把握
- データの特徴を表示:DataFrame.info()
- 要約統計量を表示:DataFrame.describe()
- データの一部を表示:DataFrame.head()、DataFrame.tail()
- データの形状を表示:DataFrame.shape
- 行数を取得:DataFrame.index.values
- 列名を取得:DataFrame.columns.values
- それぞれの列の型を取得:DataFrame.dtypes
データの切り出し(スライス)
- データのスライス:DataFrame[]、DataFrame.iloc[]、DataFrame.loc[]
- フィルタリング:DataFrame.query()
データの並べ替え
- 値による並べ替え:DataFrame.sort_values()
- インデックスによる並べ替え:DataFrame.sort_index()
- 列名の変更:DataFrame.rename()
集計
- 列の集計:DataFrame.value_counts()
- 表の集計:DataFrame.groupby()
- ※groupby().sum()で合計、groupby().mean()で平均値得ることができる
可視化
Matplotlibのimportが必要
- ヒストグラム:DataFrame.hist()
- 散布図、線グラフ:DataFrame.plot()
- 棒グラフ:DataFrame.bar()
- 箱ひげ図:DataFrame.boxplot()
欠損値の扱い
- 欠損値の確認:DataFrame.isnull().sum()
- 欠損値に値を埋める:DataFrame.fillna()
- 欠損値のある行を削除する:DataFrame.dropna()
その他
- カテゴリー変数の展開:get_dummies()
- 列同士の相関を確認:DataFrame.corr()
上記以外のことはpandasではできないと思います
ライブラリについて
pandasはデータ解析の機能を有しているライブラリですが、ライブラリというのは「ある機能のために複数のものを一つにまとめたパッケージ」みたいなものです
以下の記事で詳細に解説しているので、参考にしてください
pandas以外のライブラリについて
pandas以外にもデータ分析・解析を行うことができるライブラリはあります
- numpy
- matplotlib
- Scipy
- scikit-learn
それぞれ特徴が変わりますので、必要に応じたライブラリを選択する必要があります
基本的なデータ分析・解析などはpandasで十分だと思います
pandasのメリット
pandasは、基本的にexcelでできることはできます
しかし、繰り返し同じような作業を行う場合には、excelでは難しく、pythonなどのプログラミング言語が必要となってきます
膨大なデータで同じような作業を半自動で行ってくれるのが、pandasを使用する最大のメリットです
また、matplotlibやseabornを一緒に使えば、データの可視化まで簡単に行うことが可能です
pandasのデメリット
pandasのデメリットとしては、これまで使用したことがない場合には、コードを学ばなくてはいけない、という点があります
その点に関しては、以下の記事で解説をしているので、記事通り進めていけば、データの前処理〜統計〜可視化まで可能です
pandasの使い方
では実際にpandasを使っていきたいと思います
pandasを使うには、Anacondaの利用が便利です
Anacondaのインストール
Anacondaのインストールは簡単に行うことができるので、以下の記事を見つつ、進めていけばOKです

ライブラリのインポート
Anacondaのインストールが完了したら、コードを打っていきます
pandasのライブラリをインポートするのは、以下のコード
import pandas as pd「as」というのは、pandasを「pd」という名称で使いますよ、というおまじないです
seriesについて
pandasには「series」と「DataFrame」の2種類があります
seriesはデータが1対1の関係になっているものを指します
DataFrameについて
DataFrameとは、表計算ソフトのように、行と列で表現されます
基本的にcsvなどのファイルを読み込んだ際には、DataFrameになっています
そのため、ほとんどの場合には、このDataFrameを利用することになるため、理解を深めておくことは大切になります
pandasてcsvファイルを読み込む
実際にpandasでcsvファイルを読み込んで中身を確認していきます
import pandas as pd
file=pd.read_csv("XXXXX.csv")
print(file)csvのファイルは該当ファイルのパス名をコピペすればOKです
読み込んだファイルの要約統計量を算出する
csvファイルを読み込んだら、要約統計量を算出してみましょう
import pandas as pd
file=pd.read_csv("XXXXX.csv")
print(file.describe())これで最大値や最小値、平均値などを一気に算出することが可能です
より詳しい解説は以下の記事で行っているので、そちらも参考に進めてみてください

まとめ
- pandasを使えばデータ分析の前処理が行える
- csvからデータを読み込むことも可能
- 要約統計量の算出が簡単にできる