
研究を進めていると、最大値や平均値、中央値を算出する機会があります
この辺りはすぐに算出することができますが、四分位範囲や標準偏差などを算出するようになると、やや煩雑さが増してきます
しかし、pythonのpandasを使用すれば、全てを一度に算出すること可能になります
今回はpandasのdescribeで各データの要約統計量を算出する方法を解説していきたいと思います
サンプルコード+csvからデータを選択する方法もありますので、参考にしてみてください
pythonで統計学を学ぶ流れは以下の記事を参考にしてください
Contents
要約統計量とは?
まず、要約統計量とは、標本の分布の特徴を代表的に(要約して)表す統計学上の値で、統計量の一種です
記述統計量や基本統計量、代表値などとも呼ばれます
代表的なものに、平均値や中央値、標準偏差、標準誤差などがあります
pandasのdescribeを使用する
平均値や中央値、四分位範囲などを一度に算出するには、pandasのdescribeを使用します
今回はseabornからirisのデータをインポートしてきて、試してみたいと思います
seabornからirisデータをインポートする
まずは今回使用するirisデータをインポートします
import seaborn as sns
iris = sns.load_dataset('iris')
#.headで先頭5行を表示
print(iris.head())
上記のコードを入力後、画像のようになるはずです
seabornでインポートすると、pandasのデータフレームとして読み込まれます
pandasについて

describeを実行する
要約統計量を算出するには、pandasのdescribeを使えばOKです
コードは以下です
DataFrame.describe(percentiles=None, include=None,
exclude=None, datetime_is_numeric=False)- percentiles:数値のリスト.0~1の間で調整可能.基本的には[0.25,0.5,0.75]
- include:’all’,データ型のリストもしくはNone.どのデータ型を対象に要約統計量を返すか
- exclude:データ型のリストもしくはNone.要約統計量を返す際に、どのデータ型を含む列データを除外するかを指定
- datetime_is_numeric:日時のdtypeを数値として扱うかどうかいずれも省略可能
実際にirisデータで要約統計量を出力してみます
import seaborn as sns
iris = sns.load_dataset('iris')
print(iris.describe())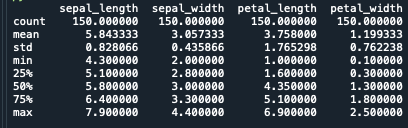
要約統計量をテキストボックスに表示させる
私は統計をかけるたびに、要約統計量をテキストボックスに表示させるようにしています
要約統計量をテキストボックスに表示させるコードは以下です
#ファイル選択画面を起動して、csvデータを選択
def wilcoxontest():
type = [("all file","*")]
file_path_stastics = filedialog.askopenfilename(filetypes = type, initialdir = os.getcwd ())
stasticsdata = pd.read_csv(file_path_stastics, engine="python",index_col=None)
#選択したcsvの任意の列を選ぶ
A_list=stasticsdata.iloc[:,2]
A=list(A_list)
B_list=stasticsdata.iloc[:,3]
B=list(B_list)
#結果の出力.p値、要約統計量を出力
result=stats.wilcoxon(A, B, alternative='two-sided')
text.insert(tk.END,stasticsdata.describe())
listbox1.insert(tk.END,"p=%.3f" %(result.pvalue))pandasを使ってirisデータのcsvを読み込む
pandasを使ってirisデータのcsvを読み込むこともできます
import pandas as pd
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
print(iris.head())(”)を以下のように変更すれば、自分のパソコン上にあるファイルを選択し、読み込むことができます
from tkinter import filedialog
import pandas as pd
import os
import csv
type = [("all file","*")]
file_path_stastics = filedialog.askopenfilename(filetypes = type, initialdir = os.getcwd ())
stasticsdata = pd.read_csv(file_path_stastics, engine="python",index_col=None).headで確認をするとseabornと同じように読み込まれているのがわかります
今度は好きな列の要約統計量を算出したいと思います
今回は「sepal_length」のみを算出してみましょう
import pandas as pd
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
A_pd=iris.iloc[:,0]
print(A_pd.describe())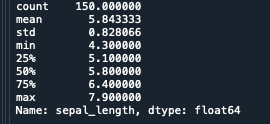
上記コードから、画像のような結果が出力されるはずです
iloc[]の数値を変更すれば、csvデータの好きな列の要約統計量を算出することが可能です
それぞれの要約統計量の算出方法
describeを使用すれば、要約統計量をまとめて算出することが可能ですが、それぞれを算出することも可能です
データ数を算出する
データ数を算出するには.count()を使用すればOKです
import pandas as pd
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
print(iris.count())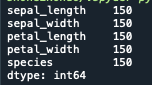
データの平均
平均を算出するには.mean()を使用します
import pandas as pd
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
print(iris.mean())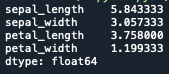
分散を算出する
分散を算出するには.var()を使用します
import pandas as pd
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
print(iris.var())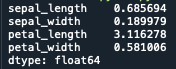
標準偏差を算出する
標準偏差を算出するには.std()を使用します
import pandas as pd
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
print(iris.std())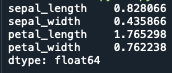
最大値と最小値を算出する
最大値には.max()、最小値には.min()を用います
import pandas as pd
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
print(iris.max())
print(iris.min())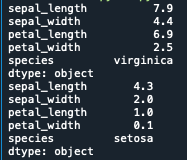
四分位数を算出する
四分位数を算出するには、.quantile()を使用します
パーセントの値は0~1の間で設定することができます
import pandas as pd
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
print(iris.quantile(q=[0.25, 0.5, 0.75]))
今回は第一四分位〜第三四分位までを算出しています
第一四分位は最小値、第二四分位は中央値になっています
第四四分位は最大値となります
まとめ
- 要約統計量はpandasのdescribeを使う
- 要約統計量を個々で算出することも可能
- 個々の要約統計量はエラーバーをつける場合などに使用
統計学やpythonについて学んだ書籍一覧



pythonの書籍を読むならkindleがおすすめ
Python学習を進めていく上で、
「ひとまず何かしらの書籍に目を通したい」
「webで調べても全くわからない」
という状況が何度も何度でも出てくるかと思います。
そういう時に便利なのが、kindleとテラテイルです。
Kindleはご存知の通り、電子書籍です。
Kindleには多くのpython学習本が用意されており、無料で読むことができます。(たまに有料もあります)
ひとまずどういった書籍があるのか?
もしものために、書籍に目を通しておこう
という場合には、kindleの利用がおすすめです。








