Pythonでcsvデータを取り込んだ際、データフレームの形で取り込まれます
取り込んだデータから、特定のデータを抽出したい場合も多々あります
今回はデータフレームで取り込んだデータから、特定の行・列を抽出し、目的の形へと加工する方法について解説していきます
Contents
データフレームとは
データフレームとは、二次元の表形式データを指します
二次元データというのは1対複数の関係であるデータ形式のことを指しています

pandasには一次元のデータもあり、それをseriesと呼びます
データを扱う場合には、その多くが二次元データであるデータフレームになるかと思います
データフレーム3つの構造
データフレームを扱う際に以下の3つの構造については知っておいたほうが、今後のデータ加工もスムーズに進むと思います
- values:実際のデータ
- columns:列名(列ラベル)
- index:行名(行ラベル)
データフレームを作成する
では今回の行・列抽出を行うためのデータフレームを作成していきたいと思います
import pandas as pd
# リスト型の配列を作る。
a = [ ,[20,50,30,40,70,60,90]]
b = ['A列','B列','C列','D列','E列','F列','G列']
d = pd.DataFrame(a, columns=b)
print(d)
,[20,50,30,40,70,60,90]]
b = ['A列','B列','C列','D列','E列','F列','G列']
d = pd.DataFrame(a, columns=b)
print(d) ,[20,50,30,40,70,60,90]]
b = ['A列','B列','C列','D列','E列','F列','G列']
d = pd.DataFrame(a, columns=b)
print(d)
,[20,50,30,40,70,60,90]]
b = ['A列','B列','C列','D列','E列','F列','G列']
d = pd.DataFrame(a, columns=b)
print(d)
上記コードを入力後、実行すると、画像のような配列が出力されます
「a」「b」のデータ数を増やせば、データフレームの配列も増えていきます
import pandas as pd
# リスト型の配列を作る。
a = [,[20,50,30,40,70,60,90,55] ,,
[11,14,56,63,12,55,67,14],]
b = ['A列','B列','C列','D列','E列','F列','G列']
d = pd.DataFrame(a, columns=b)
print(d)
 ,
[11,14,56,63,12,55,67,14],
,
[11,14,56,63,12,55,67,14],上記のように列数に対して、データの数が上回ると以下のようなエラーが出ます
File "/opt/anaconda3/lib/python3.8/site-packages/pandas/core/internals/construction.py", line 568, in _list_to_arrays
columns = _validate_or_indexify_columns(content, columns)
File "/opt/anaconda3/lib/python3.8/site-packages/pandas/core/internals/construction.py", line 692, in _validate_or_indexify_columns
raise AssertionError(
AssertionError: 7 columns passed, passed data had 8 columns
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Users/untitled0.py", line 14, in <module>
d = pd.DataFrame(a, columns=b)
File "/opt/anaconda3/lib/python3.8/site-packages/pandas/core/frame.py", line 570, in __init__
arrays, columns = to_arrays(data, columns, dtype=dtype)
File "/opt/anaconda3/lib/python3.8/site-packages/pandas/core/internals/construction.py", line 528, in to_arrays
return _list_to_arrays(data, columns, coerce_float=coerce_float, dtype=dtype)
File "/opt/anaconda3/lib/python3.8/site-packages/pandas/core/internals/construction.py", line 571, in _list_to_arrays
raise ValueError(e) from e
ValueError: 7 columns passed, passed data had 8 columnsデータ数と列数が一致してないですよ、ということです
データフレームを作成する場合には気をつけておきましょう
少しデータ数を増やして、それを加工していきます
import pandas as pd
# リスト型の配列を作る。
a = [,[20,50,30,40,70,60,90] ,,
[11,14,56,63,12,55,67],]
b = ['A列','B列','C列','D列','E列','F列','G列']
d = pd.DataFrame(a, columns=b)
print(d)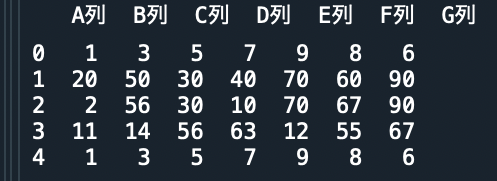
データフレームから抽出する
では、先ほど作成したデータフレームを元に行or列の抽出を行っていきたいと思います
特定の行の抽出
特定の行を抽出したい場合には:(コロン)で行番号を指定することで、可能となります
import pandas as pd
# リスト型の配列を作る。
a = [,[20,50,30,40,70,60,90] ,,
[11,14,56,63,12,55,67],]
b = ['A列','B列','C列','D列','E列','F列','G列']
d = pd.DataFrame(a, columns=b)
#1行目から3行目を抽出
print(d)
特定の列を抽出する
pandasで特定の列を抽出するには、カラム名(列名)を指定することで、特定の列を抽出することが可能です
import pandas as pd
# リスト型の配列を作る。
a = [,[20,50,30,40,70,60,90] ,,
[11,14,56,63,12,55,67],]
b = ['A列','B列','C列','D列','E列','F列','G列']
d = pd.DataFrame(a, columns=b)
#1行目から3行目を抽出
print(d['A列'])[”]で指定せずに、.(ドット)を利用しても、特定の列を抽出することが可能です
import pandas as pd
# リスト型の配列を作る。
a = [,[20,50,30,40,70,60,90] ,,
[11,14,56,63,12,55,67],]
b = ['A列','B列','C列','D列','E列','F列','G列']
d = pd.DataFrame(a, columns=b)
#1行目から3行目を抽出
print(d.A列)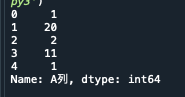
locを使用して特定の行・列を抽出する
locを使うことで、特定の行や列を抽出することが可能です
import pandas as pd
# リスト型の配列を作る。
a = [,[20,50,30,40,70,60,90] ,,
[11,14,56,63,12,55,67],]
b = ['A列','B列','C列','D列','E列','F列','G列']
d = pd.DataFrame(a, columns=b)
#A列とB列を抽出
print(d.loc[:,['A列','B列']])
import pandas as pd
# リスト型の配列を作る。
a = [,[20,50,30,40,70,60,90] ,,
[11,14,56,63,12,55,67],]
b = ['A列','B列','C列','D列','E列','F列','G列']
d = pd.DataFrame(a, columns=b)
#C列のみ抽出
print(d.loc[:,['C列']])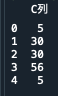
ilocで行・列を指定して、行・列を抽出する
ilocを使用することで、行・列を指定して、行・列を抽出することが可能です
import pandas as pd
# リスト型の配列を作る。
a = [,[20,50,30,40,70,60,90] ,,
[11,14,56,63,12,55,67],]
b = ['A列','B列','C列','D列','E列','F列','G列']
d = pd.DataFrame(a, columns=b)
#すべての行と1列目を抽出
print(d.iloc[:,1])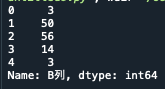
import pandas as pd
# リスト型の配列を作る。
a = [,[20,50,30,40,70,60,90] ,,
[11,14,56,63,12,55,67],]
b = ['A列','B列','C列','D列','E列','F列','G列']
d = pd.DataFrame(a, columns=b)
#1行目と2列目を取得
print(d.iloc,)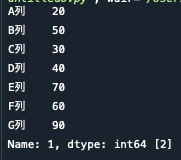
locやilocを使った詳しい解説はこちらを参考にしてください

まとめ
- 特定の行の抽出:(コロンで指定)
- 特定の列の抽出はカラム名で抽出
- 特定の行・列を抽出はlocを使用
- 行・列を指定して、行・列を抽出はilocを使用