
統計学の教科書を読んでいると、一番最初に度数分布とヒストグラムなどが記載されています
どちらも統計学を学んでいく上で、大切な項目になるので、ぜひ一緒に勉強をしていきましょう
これまでの【pythonで統計学】同様、csvファイルを読み込んでヒストグラムを作成するサンプルコードもお伝えします!
pythonで統計学を学ぶ流れは以下の記事を参考にしてください
Contents
ヒストグラムとは?
ヒストグラムとは、ある特定のデータを区間ごとに区切り、各区間の個数や数値のばらつきを棒グラフ様の図で作られているグラフです
ヒストグラムを作成することで、数値で集めた度数分布表を視覚的にわかりやすく表現することができます
度数分布表とは
度数分布表とは、収集したデータをある幅ごとに区切って、その中に含まれるデータの個数を見るための数値をまとめた表です
1つの区間を階級と呼びますが、binと呼ぶこともあります
pythonのコードではbin,binsを用いています
| 175 | 159 | 178 | 155 | 173 |
| 176 | 161 | 155 | 152 | 172 |
| 156 | 152 | 173 | 180 | 180 |
| 155 | 178 | 172 | 160 | 168 |
| 165 | 155 | 180 | 166 | 158 |
| 178 | 173 | 168 | 167 | 151 |
| 161 | 172 | 158 | 162 | 157 |
| 169 | 180 | 151 | 173 | 174 |
| 171 | 168 | 157 | 155 | 178 |
| 180 | 158 | 174 | 165 | 155 |
| 160 | 151 | 180 | 178 | 173 |
| 166 | 157 | 166 | 161 | 172 |
| 167 | 174 | 155 | 169 | 180 |
| 162 | 180 | 152 | 171 | 168 |
| 173 | 166 | 180 | 180 | 158 |
| 168 | 155 | 160 | 168 | 151 |
| 179 | 152 | 166 | 179 | 157 |
| 166 | 167 | 167 | 166 | 174 |
| 175 | 156 | 162 | 175 | 168 |
| 172 | 180 | 173 | 156 | 179 |
| 167 | 177 | 180 | 180 | 166 |
上記の様な身長を集めたデータがあったとします
これだけではデータの羅列であり、このデータの特徴をパッと見ただけでは把握することができません
そこで、まずは身長が低い順番に並べ替えていきます
| 151 | 157 | 166 | 172 | 178 |
| 151 | 157 | 166 | 172 | 178 |
| 151 | 158 | 166 | 172 | 178 |
| 151 | 158 | 166 | 172 | 178 |
| 152 | 158 | 166 | 172 | 178 |
| 152 | 158 | 167 | 173 | 179 |
| 152 | 159 | 167 | 173 | 179 |
| 152 | 160 | 167 | 173 | 179 |
| 155 | 160 | 167 | 173 | 180 |
| 155 | 160 | 167 | 173 | 180 |
| 155 | 161 | 168 | 173 | 180 |
| 155 | 161 | 168 | 173 | 180 |
| 155 | 161 | 168 | 174 | 180 |
| 155 | 162 | 168 | 174 | 180 |
| 155 | 162 | 168 | 174 | 180 |
| 155 | 162 | 168 | 174 | 180 |
| 156 | 165 | 168 | 175 | 180 |
| 156 | 165 | 169 | 175 | 180 |
| 156 | 166 | 169 | 175 | 180 |
| 157 | 166 | 171 | 176 | 180 |
| 157 | 166 | 171 | 177 | 180 |
小さい順に並べ替えたら、150cm代,160cm代…というふうに分けていきます
今回の場合だと、
- 黄色:28個
- オレンジ:33個
- 水色:31個
- 白:13個
というふうになり、これをまとめると以下のようになります
| 階級 | 度数 |
| 150〜159 | 28 |
| 160〜169 | 33 |
| 170〜179 | 31 |
| 180〜 | 13 |
| 合計 | 105 |
階級は「データを区切る範囲」、度数は「データの個数」を表しています
このように度数分布表としてまとめることで、階級と度数の関係性がわかりやすくなります
さらにデータを加工していくと以下のようになります
| 階級 | 度数 | 累積度数 | 相対度数 | 累積相対度数 |
| 150〜159 | 28 | 28 | 0.26 | 0.26 |
| 160〜169 | 33 | 61 | 0.31 | 0.58 |
| 170〜179 | 31 | 92 | 0.29 | 0.87 |
| 180〜 | 13 | 105 | 0.12 | 1 |
| 合計 | 105 | なし | 1 | なし |
それぞれの言葉の意味は以下のようになります
- 階級:データを区切る範囲
- 度数:データの個数
- 累積度数:その階級までのすべての度数の合計
- 相対度数:それぞれの階級の度数が全体に占める割合
- 累積相対度数:その階級までのすべての相対度数の合計
このような度数分布表だけでも、データの分散度合いや中央値を知ることができますが、ヒストグラムを作成すれば、数値だけではなく、視覚的にも理解しやすくなります
pythonでヒストグラムを作成する方法
ではここからはpythonでヒストグラムを作成する方法について解析していきたいと思います
ヒストグラムを作成する場合には、matplotlib.pyplot.histを使用します
コードはこちら
matplotlib.pyplot.hist(x, bins=None, range=None, density=False, weights=None,
cumulative=False, bottom=None, histtype='bar', align='mid',
orientation='vertical', rwidth=None, log=False, color=None,
label=None, stacked=False, *, data=None, **kwargs)パラメータが多めです
| x (必須) | ヒストグラムを作成するための生データの配列。 |
|---|---|
| bins | ビン (表示する棒) の数。階級数。(デフォルト値: 10) |
| range | ビンの最小値と最大値を指定。(デフォルト値: (x.min(), x.max())) |
| normed | True に設定すると正規化 (合計値が 1 になるように変換) を実施。 (デフォルト値: False) |
| cumulative | True に設定すると、累積ヒストグラムを出力。 (デフォルト値: False) |
| bottom | 各棒の下側の余白を数値または配列で指定。 |
| histtype | ‘bar’ (通常のヒストグラム), ‘barstacked’ (積み上げヒストグラム), ‘step’ (線), ‘stepfilled ‘ (塗りつぶしありの線) から選択。 (デフォルト値: ‘bar’) |
| align | 各棒の中心を X 軸目盛上のどの横位置で出力するか。 ‘left’, ‘mid’, ‘right’ から選択。(デフォルト値: ‘mid’) |
| orientation | 棒の方向。’horizontal’ (水平方向), ‘vertical’ (垂直方向) から選択。(デフォルト値: ‘vertical’) |
| rwidth | 各棒の幅を数値または、配列で指定。 |
| log | True に設定すると、縦軸を対数目盛で表示します。 |
| color | ヒストグラムの色。配列で指定し、データセット単位で色を指定することができます。 |
| label | 凡例を載せる際に使用します。 |
| stacked | True に設定すると積み上げヒストグラムで出力します。False に設定すると、横に並べて出力します。 |
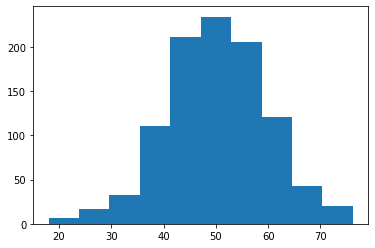
import numpy as np
import matplotlib.pyplot as plt
x = np.random.normal(50, 10, 1000)
plt.hist(x)
seabornを使用してヒストグラムを作成する方法
matplotlibでヒストグラムを作成するのもいいですが、seabornを使用するとより綺麗なグラフを作成することができます
コードはこちら
seaborn.distplot(a=None, bins=None, hist=True, kde=True, rug=False,
fit=None, hist_kws=None, kde_kws=None, rug_kws=None, fit_kws=None,
color=None, vertical=False, norm_hist=False, axlabel=None, label=None,
ax=None, x=None)パラメーターが多いですが、覚えておきたいのは以下の数種類
| オプション | 説明 |
|---|---|
data | Seriesまたは1d-array、listのみ |
bins | 等級値(x軸の刻み目)の数。 |
color | 色の指定 |
label | 凡例の指定。plt.legend()必須。 |
kde | True:密度近似関数の描画 |
rug | True:実数値の描画 |
fit | norm:正規分布の描画 |
それ以外は公式サイトを参考にしてください
#seabornをインポート.sns.set()はグラフを綺麗にするおまじない
import seaborn as sns; sns.set()seabornにはあらかじめ用意されているデータがあり、ここからはそちらを使っていきたいと思います
#あらかじめ用意されているirisのデータを使用
iris = sns.load_dataset('iris') 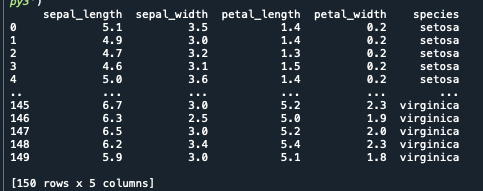
sns.distplot(
iris['sepal_width'], bins=13, label='data',
kde=False,
rug=False
)
plt.legend() # 凡例を表示
plt.show() # ヒストグラムを表示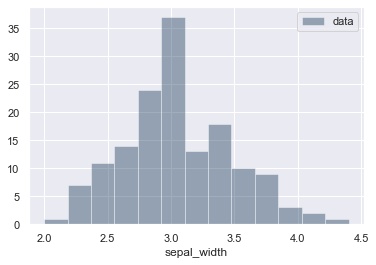
#色の指定なしのヒストグラム
from matplotlib import pyplot as plt
import seaborn as sns; sns.set()
iris = sns.load_dataset('iris')
sns.distplot(
iris['sepal_width'], bins=13, label='data',
kde=False,
rug=False
)
plt.legend() # 凡例を表示
plt.show() # ヒストグラムを表示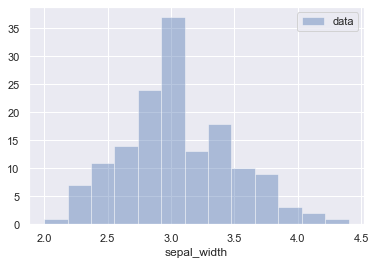
#別色ヒストグラム
from matplotlib import pyplot as plt
import seaborn as sns; sns.set()
iris = sns.load_dataset('iris')
sns.distplot(
iris['sepal_width'], bins=13, color='#A0522D',label='data',
kde=False,
rug=False
)
plt.legend() # 凡例を表示
plt.show() # ヒストグラムを表示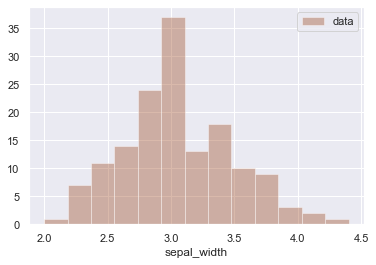
seabornで色を変える場合には、以下のサイトを参考にしてみてください
seabornのヒストグラムに正規分布を加える
seabornにfit=normを加えることで、正規分布を描画することができます
from matplotlib import pyplot as plt
import seaborn as sns; sns.set()
from scipy.stats import norm
iris = sns.load_dataset('iris')
sns.distplot(
iris['sepal_width'], bins=13, color='#A0522D',label='data',
kde_kws={'label': 'kde','color':'k'},
fit=norm,fit_kws={'label': 'norm','color':'red'},
rug=False
)
plt.legend() # 凡例を表示
plt.show() # ヒストグラムを表示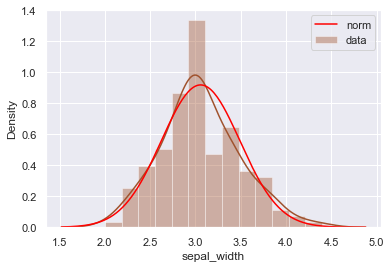
csvから読み込んだデータでヒストグラムを作る
from matplotlib import pyplot as plt
import seaborn as sns; sns.set()
from scipy.stats import norm
import os
from tkinter import filedialog
type = [("all file","*")]
file_path_stastics = filedialog.askopenfilename(filetypes = type, initialdir = os.getcwd ())
stasticsdata = pd.read_csv(file_path_stastics, engine="python",index_col=None)
A_list=stasticsdata.iloc[:,2]
iris=list(A_list)
sns.distplot(
iris['sepal_width'], bins=13, color='#A0522D',label='data',
kde_kws={'label': 'kde','color':'k'},
fit=norm,fit_kws={'label': 'norm','color':'red'},
rug=False
)
plt.legend() # 凡例を表示
plt.show() # ヒストグラムを表示
読み込みたいcsvデータを選択し、選択したcsvデータの好きな列(今回の場合は3列目)をirisとして代入すれば、同じようなグラフを描画することができます
まとめ
- ヒストグラムは度数分布の視認性を高める
- グラフを描画する場合にはmatplotlibもしくはseaborn
- seabornは簡単に綺麗なグラフを作成できる
- ヒストグラム+正規分布も可能
統計学やpythonについて学んだ書籍一覧



pythonの書籍を読むならkindleがおすすめ
Python学習を進めていく上で、
「ひとまず何かしらの書籍に目を通したい」
「webで調べても全くわからない」
という状況が何度も何度でも出てくるかと思います。
そういう時に便利なのが、kindleとテラテイルです。
Kindleはご存知の通り、電子書籍です。
Kindleには多くのpython学習本が用意されており、無料で読むことができます。(たまに有料もあります)
ひとまずどういった書籍があるのか?
もしものために、書籍に目を通しておこう
という場合には、kindleの利用がおすすめです。








