
SNSといえば「ハッシュタグ」ですよね
今回はpythonを使ってtwitterのハッシュタグを検索・csvに記録する方法について解説していきたいと思います
どういったハッシュタグがよく使われているのか?を知ることで、市場調査をすることができます
市場調査を行うことで、マーケティングの一助にすることもできますので、ぜひ利用してみてください
pythonでtwitterを操作してみたい
pythonでtwitterのハッシュタグを取得した
という方向けに、pythonでtwitterのハッシュタグを検索・記録する方法について解説していきます
以下の記事では、pythonでtwitterを使う方法をまとめて解説しているので、参考にしてみてください
pythonでtwitterを扱えるようになると、twitterで行われている懸賞に自動で応募することができるようになります
pythonを使ったtwitter自動化-twitter懸賞自動応募で当選実績あり-
Contents
pythonでtwitterのハッシュタグを検索し記録する方法

このコードではtwitter APIを使用して実行していくため、twitter APIの取得がまだの場合には、先にこちらの記事を参考にtwitter APIの取得をしておきましょう
まずは全体のコードから
検索のキーワードを「#」にすることで、ハッシュタグ検索をすることができます
また、フィルターでいいねが〇〇件以上、リツイートは除外する、などを設定することができます
抽出したツイートはcsvに出力させています
# ライブラリのインポート
import tweepy
from datetime import datetime,timezone
import pytz
import pandas as pd
#Twitter情報。
#********には自分自身のAPIキーなどを入力してください
consumer_key = '********'
consumer_secret = '********'
access_token = '********'
access_token_secret = '********'
#Twitterの認証
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
# ”wait_on_rate_limit = True” 利用制限にひっかかた時に必要時間待機する
api=tweepy.API(auth,wait_on_rate_limit=True)
# 検索条件の設定
search_word = '# min_faves:200 -filter:retweets'
#何件のツイートを取得するか
item_number = 300
#検索条件を元にツイートを抽出
tweets = tweepy.Cursor(api.search_tweets,q=search_word, tweet_mode='extended',result_type="mixed",lang='ja').items(item_number)
#関数: UTCをJSTに変換する
def change_time_JST(u_time):
#イギリスのtimezoneを設定するために再定義する
utc_time = datetime(u_time.year, u_time.month,u_time.day, \
u_time.hour,u_time.minute,u_time.second, tzinfo=timezone.utc)
#タイムゾーンを日本時刻に変換
jst_time = utc_time.astimezone(pytz.timezone("Asia/Tokyo"))
# 文字列で返す
str_time = jst_time.strftime("%Y-%m-%d_%H:%M:%S")
return str_time
#抽出したデータから必要な情報を取り出す
#取得したツイートを一つずつ取り出して必要な情報をtweet_dataに格納する
tw_data = []
for tweet in tweets:
#ツイート時刻とユーザのアカウント作成時刻を日本時刻にする
tweet_time = change_time_JST(tweet.created_at)
create_account_time = change_time_JST(tweet.user.created_at)
#tweet_dataの配列に取得したい情報を入れていく
tw_data.append([
tweet.id,
tweet_time,
tweet.full_text,
tweet.favorite_count,
tweet.retweet_count,
tweet.user.id,
tweet.user.screen_name,
tweet.user.name,
tweet.user.description,
tweet.user.friends_count,
tweet.user.followers_count,
create_account_time,
tweet.user.following,
tweet.user.profile_image_url,
tweet.user.profile_background_image_url,
tweet.user.url
])
#取り出したデータをpandasのDataFrameに変換
#CSVファイルに出力するときの列の名前を定義
labels=[
'ツイートID',
'ツイート時刻',
'ツイート本文',
'いいね数',
'リツイート数',
'ID',
'ユーザー名',
'アカウント名',
'自己紹介文',
'フォロー数',
'フォロワー数',
'アカウント作成日時',
'自分のフォロー状況',
'アイコン画像URL',
'ヘッダー画像URL',
'WEBサイト'
]
#tw_dataのリストをpandasのDataFrameに変換
df = pd.DataFrame(tw_data,columns=labels)
#CSVファイルに出力する
#CSVファイルの名前を決める
file_name='./tw_data.csv'
#CSVファイルを出力する
df.to_csv(file_name,encoding='utf-8-sig',index=False)
twitterのツイートを検索・取得のオプション
search_wordの後ろに付け加えることができるオプションは以下のようになっています
| 検索キーワード | 説明 |
| キーワード -除外するキーワード | -の後に続くキーワードを除外して検索 |
| キーワード min_faves:100 | いいねの数が100以上のツイートだけ |
| キーワード min_retweets:100 | 100リツイート以上のツイートを検索 |
| from:ユーザーネーム | 特定のユーザーのツイートを検索 |
| キーワード1 OR キーワード2 | ブログもしくはブロガーのキーワードを検索 |
| “キーワード” | ” “で囲われた文字列に完全一致するツイートを検索 |
ハッシュタグだけ抜き出す
ツイート情報を抜き出したら、今度はそこからハッシュタグ情報だけ抜き出していきます
ここからはハッシュタグを抜き出し、可視化するコードを
続き
・
・
・
#tw_dataのリストをpandasのDataFrameに変換
df = pd.DataFrame(tw_data,columns=labels)
hash_lists = df['ツイート本文'].apply(lambda x:re.findall(r"#\S*", str(x)))
print(hash_lists)
marge_list=[]
for hash_list in hash_lists:
if hash_list:
marge_list=marge_list + hash_list
Se_hash = pd.Series(marge_list)
df_hash = Se_hash.value_counts()
df_hash = df_hash.reset_index(name='Num').set_axis(['unique_hash','Num'],axis='columns')
print(df_hash)
#プロットする範囲だけ抽出
x_values=df_hash['unique_hash'][0:19]
y_values=df_hash['Num'][0:19]
fig,ax = plt.subplots(1,1,figsize=(16,8),facecolor='white',linewidth=1,edgecolor='black')
sns.barplot(x=x_values,y=y_values,palette="jet_r",ax=ax)
#グラフのタイトルをつける
ax.set_title('ハッシュタグ分析')
#y軸の範囲を決める
ax.set_ylim(0,10)
#軸のタイトルを決める
ax.set_xlabel('ハッシュタグ',fontsize=14)
ax.set_ylabel('使われた回数',fontsize=14)
#軸ラベルの書式設定
ax.tick_params(axis='x',labelrotation=90,labelsize=10)
ax.tick_params(axis='y',labelsize=14)
#グラフの下に20%の空白を入れる
fig.subplots_adjust(bottom=0.35)
#データラベルを表示
cnt = 0
for y_value in y_values:
plt.text(x=cnt,y=y_value+1,s=str(y_value),horizontalalignment="center",fontsize=12)
cnt += 1
#画像を保存
fig.savefig('ハッシュタグ.png')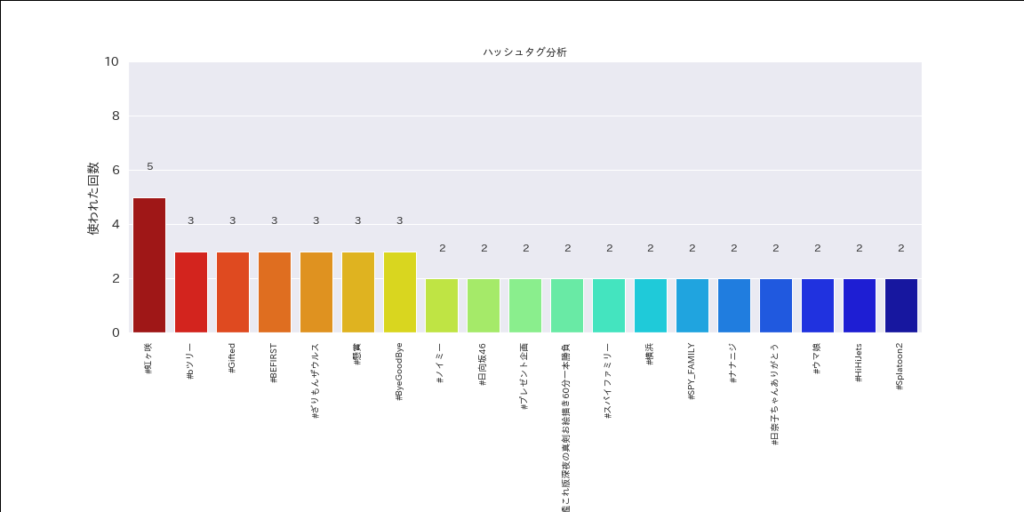
本記事全体のコード
matplotlibは日本語に対応していないので、日本語を扱うときには、文字化けしてしまいます
それの対策として、あらかじめ日本語対応のフォントを指定しておきます
「plt.rcParams[‘font.family’] = ‘AppleGothic’ 」
Macの場合は、上記を記載しておくと、文字化けを回避することができます
# ライブラリのインポート
import tweepy
from datetime import datetime,timezone
import pytz
import pandas as pd
import re
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
plt.rcParams['font.family'] = 'AppleGothic'
# Twitterの認証
#Twitter情報。
#********には自分自身のAPIキーなどを入力してください
consumer_key = '********'
consumer_secret = '********'
access_token = '********'
access_token_secret = '********'
#Twitterの認証
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
# ”wait_on_rate_limit = True” 利用制限にひっかかた時に必要時間待機する
api=tweepy.API(auth,wait_on_rate_limit=True)
# 検索条件の設定
search_word = '# min_faves:200 -filter:retweets'
#何件のツイートを取得するか
item_number = 300
#検索条件を元にツイートを抽出
tweets = tweepy.Cursor(api.search_tweets,q=search_word, tweet_mode='extended',result_type="mixed",lang='ja').items(item_number)
#関数: UTCをJSTに変換する
def change_time_JST(u_time):
#イギリスのtimezoneを設定するために再定義する
utc_time = datetime(u_time.year, u_time.month,u_time.day, \
u_time.hour,u_time.minute,u_time.second, tzinfo=timezone.utc)
#タイムゾーンを日本時刻に変換
jst_time = utc_time.astimezone(pytz.timezone("Asia/Tokyo"))
# 文字列で返す
str_time = jst_time.strftime("%Y-%m-%d_%H:%M:%S")
return str_time
#抽出したデータから必要な情報を取り出す
#取得したツイートを一つずつ取り出して必要な情報をtweet_dataに格納する
tw_data = []
for tweet in tweets:
#ツイート時刻とユーザのアカウント作成時刻を日本時刻にする
tweet_time = change_time_JST(tweet.created_at)
create_account_time = change_time_JST(tweet.user.created_at)
#tweet_dataの配列に取得したい情報を入れていく
tw_data.append([
tweet.id,
tweet_time,
tweet.full_text,
tweet.favorite_count,
tweet.retweet_count,
tweet.user.id,
tweet.user.screen_name,
tweet.user.name,
tweet.user.description,
tweet.user.friends_count,
tweet.user.followers_count,
create_account_time,
tweet.user.following,
tweet.user.profile_image_url,
tweet.user.profile_background_image_url,
tweet.user.url
])
#取り出したデータをpandasのDataFrameに変換
#CSVファイルに出力するときの列の名前を定義
labels=[
'ツイートID',
'ツイート時刻',
'ツイート本文',
'いいね数',
'リツイート数',
'ID',
'ユーザー名',
'アカウント名',
'自己紹介文',
'フォロー数',
'フォロワー数',
'アカウント作成日時',
'自分のフォロー状況',
'アイコン画像URL',
'ヘッダー画像URL',
'WEBサイト'
]
#tw_dataのリストをpandasのDataFrameに変換
df = pd.DataFrame(tw_data,columns=labels)
hash_lists = df['ツイート本文'].apply(lambda x:re.findall(r"#\S*", str(x)))
print(hash_lists)
marge_list=[]
for hash_list in hash_lists:
if hash_list:
marge_list=marge_list + hash_list
Se_hash = pd.Series(marge_list)
df_hash = Se_hash.value_counts()
df_hash = df_hash.reset_index(name='Num').set_axis(['unique_hash','Num'],axis='columns')
print(df_hash)
#プロットする範囲だけ抽出
x_values=df_hash['unique_hash'][0:19]
y_values=df_hash['Num'][0:19]
fig,ax = plt.subplots(1,1,figsize=(16,8),facecolor='white',linewidth=1,edgecolor='black')
sns.barplot(x=x_values,y=y_values,palette="Greens_r",ax=ax)
#グラフのタイトルをつける
ax.set_title('ハッシュタグ分析')
#y軸の範囲を決める
ax.set_ylim(0,10)
#軸のタイトルを決める
ax.set_xlabel('ハッシュタグ',fontsize=14)
ax.set_ylabel('使われた回数',fontsize=14)
#軸ラベルの書式設定
ax.tick_params(axis='x',labelrotation=90,labelsize=10)
ax.tick_params(axis='y',labelsize=14)
#グラフの下に20%の空白を入れる
fig.subplots_adjust(bottom=0.35)
#データラベルを表示
cnt = 0
for y_value in y_values:
plt.text(x=cnt,y=y_value+1,s=str(y_value),horizontalalignment="center",fontsize=12)
cnt += 1
#画像を保存
fig.savefig('ハッシュタグ.png')matplotlibの文字化け対策
あらかじめフォントを指定しておくことで、文字化けを防ぐことができますが、
japanize_matplotlibをpipでインストールしておけば、フォントを指定しなくても、文字化け対策をすることができます
pip install japanize-matplotlibあとは「import japanize_matplotlib」でコードを書いていくだけでOKです
ツイートの取得件数を増やすことにより、twitterのハッシュタグ分析量も増やすことでできるので、必要に応じて変更させればOKです
pythonの知識・技術を上げたい

pythonの知識・技術を上げて、手っ取り早く収益を上げたい
と思っている方が大半かと思います
僕はpythonを初めて10ヶ月で収益5桁を突破しました
突破した方法は以下の記事で解説していますが、もっと早く収益を出すならばスクールに通うのが一番です

以下の記事では無料体験ができるおすすめのプログラミングスクールを紹介しています
おすすめプログラミングスクール(無料体験あり)









