
統計解析を行う際に気をつけないといけないのが、「データの種類」です
データの種類は大きく分けて、4種類あります
- 名義尺度
- 順序尺度
- 間隔尺度
- 比例尺度
上二つのデータを質的データ
下二つのデータを量的データと呼んだりします
質的・量的データで使用することができる統計検定も変わってきますので、今回はデータの種類と扱い方について、解説していきたいと思います
また、以下の記事からpythonで統計学を順序立てて学ぶことができるようになっているので、参考にしてみてください
Contents
データの種類
統計検定を行う際に出てくるデータは以下のように分けられます

質的データと量的データ
質的データは性別や居住地・勤務地、血液型などが該当します
それに対して量的データは身長、体重、貯金額、気温などが該当します
アンケートなどの、
1:とてもいい
2:いい
3:普通
などは、数値の順番になっていますが、数値自体は四則演算ができないため、質的データになります
データの次元
また種類のほかに「データの次元」という分け方もあります
| 身長 |
| 175 |
| 165 |
| 183 |
| 155 |
| 147 |
上記のようなデータは一次元データと呼ばれます
また、下記のようなデータはN次元データと呼ばれます
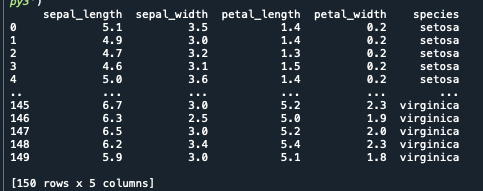
上記のirisデータは以下のコードで入手することができます
import pandas as pd
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
print(iris.head())
データを解析してみる
では実際に量的データの解析をしてみたいと思います
今回使用するのは、上述したirisのデータを使用します
import pandas as pd
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
print(iris.head())今回はこのirisデータから要約統計量を算出してみたいと思います
詳しい解説は以下の記事を参考にしてください

import pandas as pd
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
print(iris.describe())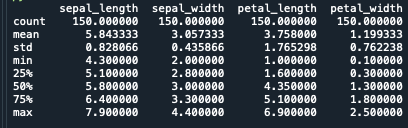
上記のコードで画像のような結果が表示されるかと思います
量的データは四分位数や平均値、最大値などを算出することができます
量的データを可視化する
要約統計量だけを算出しても視覚的にはわかりにくいので、今度はそれを可視化していきます
可視化するにはmatlibplotやseabornなどを使用します
seabornだと綺麗なグラフを作ることができるので、今回はseabornを使用します
from matplotlib import pyplot as plt
import seaborn as sns; sns.set()
#あらかじめ用意されているirisのデータを使用
iris = sns.load_dataset('iris')
sns.distplot(
iris['sepal_width'], bins=13, label='data',
kde=False,
rug=False
)
plt.legend() # 凡例を表示
plt.show() # ヒストグラムを表示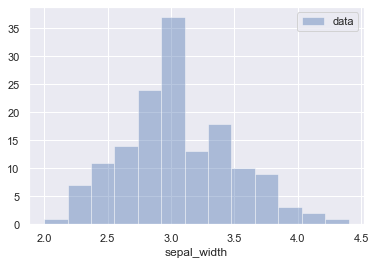
また、平均値を算出して、それをグラフ化するには以下のコードを入力します
from matplotlib import pyplot as plt
import seaborn as sns; sns.set()
import pandas as pd
#あらかじめ用意されているirisのデータを使用
iris = sns.load_dataset('iris')
sepal_length=iris.iloc[:,0]
sepal_width=iris.iloc[:,1]
print(sepal_length.mean(),sepal_width.mean())
data=[["iris",sepal_length.mean(),sepal_width.mean()]]
df=pd.DataFrame(data,columns=["name","sepal_length","sepal_width"])
color=["r","b"]
df.plot(x="name",y=["sepal_length","sepal_width"],kind="bar",color=color,figsize=(4,3))
plt.show()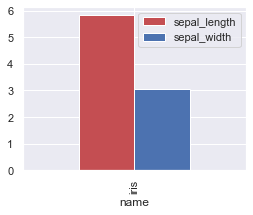
質的データを解析する
続いて質的データも解析してみます
よく用いられている「クロス集計」を行なっていきたいと思います
pythonでクロス集計を作成する場合には、
pd.crosstab()を使用します
実際のコードは以下
from matplotlib import pyplot as plt
import seaborn as sns; sns.set()
import pandas as pd
#あらかじめ用意されているirisのデータを使用
iris = sns.load_dataset('iris')
sepal_length=iris.iloc[:,0]
sepal_width=iris.iloc[:,1]
species=iris.iloc[:,4]
data=[["iris",sepal_length.mean(),sepal_width.mean()]]
df=pd.DataFrame(data,columns=["name","sepal_length","sepal_width"])
color=["r","b"]
df.plot(x="name",y=["sepal_length","sepal_width"],kind="bar",color=color,figsize=(4,3))
#下2行がクロス集計
cross=pd.crosstab(sepal_length,species)
print(cross)
plt.show()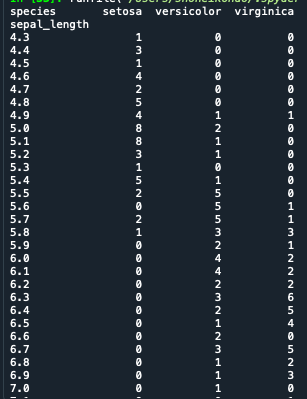
今回はそれぞれの種類にsepal_lengthの各値がどれくらいあるかを集計しています
cross=pd.crosstab(sepal_length,species)
print(cross)sepal_length,speciesを変えれば、他の集計も行うことが可能です
そのままカラーマップも作成していきましょう
from matplotlib import pyplot as plt
import seaborn as sns; sns.set()
import pandas as pd
#あらかじめ用意されているirisのデータを使用
iris = sns.load_dataset('iris')
sepal_length=iris.iloc[:,0]
sepal_width=iris.iloc[:,1]
species=iris.iloc[:,4]
data=[["iris",sepal_length.mean(),sepal_width.mean()]]
df=pd.DataFrame(data,columns=["name","sepal_length","sepal_width"])
color=["r","b"]
df.plot(x="name",y=["sepal_length","sepal_width"],kind="bar",color=color,figsize=(4,3))
cross=pd.crosstab(sepal_length,species)
print(cross)
#カラーマップ作成
ax = plt.subplots()
heatmap = plt.pcolor(cross, cmap=plt.cm.Blues)
plt.show()
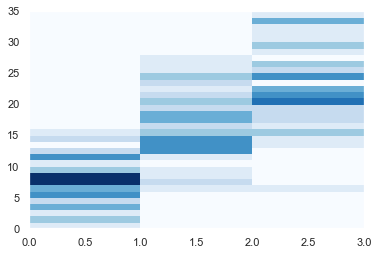
まとめ
- データには質的データと量的データがある
- 質的データ・量的データは解析方法が異なる
- 解析結果の可視化はseabornを使用











