
統計検定を行う際には、データの代表値を算出して、傾向をみることが多いと思います
pythonを使えば、データの代表値を簡単に算出することが可能です
今回はpythonでデータの代表値を算出する方法について解説していきたいと思います
また、こちらの記事からpythonで統計学を順序立てて学ぶことができるようにまとめているので、参考にしてみてください
Contents
データの代表値
データの代表値とは、「一組のデータに含まれる情報を1つの数値で表すこと」です
計算的代表値と位置的代表値の二種類があります
計算的代表値
計算的代表値は、
- 算術平均:データの総和をデータの個数で割ったもの(ただの平均値)
- 幾何平均:個々のデータの相乗積のN乗根幾何平均
- 調和平均:各データの逆数の算術平均の逆数
- 平方平均:算術平均の平方根
などに分類されます
位置的代表値
位置的代表値には、
- 中央値:測定値を小さい順に並べた時に、ちょうど真ん中にくる値
平均のように両端の値に左右されない - 最頻値:一組のデータの中で最も多く存在する値
- 四分位数:昇順に配列された全データの25%,50%,75%に位置するデータ
などがあります
統計処理を行う際に使用するのは中央値・算術平均・四分位数が多いかと思います
上記3つのデータの代表値をpythonで表現していきたいと思います
pythonでデータの代表値を算出する
では実際にpythonでデータの代表値を算出していきたいと思います
今回は無料配布されているirisのデータをpandasからインポートして使用していきます
算術平均を算出する
まずは算術平均を算出していきます
import pandas as pd
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
print(iris.mean())中央値を算出する
次は中央値を算出します
.median()で中央値を算出することができます
import pandas as pd
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
print(iris.median())四分位数を算出する
最後は四分位数を算出します
四分位数を算出するには、.quantile()を使用します
パーセントの値は0~1の間で設定することができます
import pandas as pd
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
print(iris.quantile(q=[0.25, 0.5, 0.75]))データの可視化
算出したそれぞれのデータの代表値をわかりやすいように可視化していきます
中央値は四分位範囲の第二四分位数に該当するので、平均を表す棒グラフと、四分位範囲を表す箱ひげ図を作成していきたいと思います
棒グラフの作成
棒グラフを作成するには、matplotlib.pyplot.barやseaborn、pandasなどで作成することができます
from matplotlib import pyplot as plt
import seaborn as sns; sns.set()
import pandas as pd
#あらかじめ用意されているirisのデータを使用
iris = sns.load_dataset('iris')
sepal_length=iris.iloc[:,0]
sepal_width=iris.iloc[:,1]
print(sepal_length.mean(),sepal_width.mean())
data=[["iris",sepal_length.mean(),sepal_width.mean()]]
df=pd.DataFrame(data,columns=["name","sepal_length","sepal_width"])
color=["r","b"]
df.plot(x="name",y=["sepal_length","sepal_width"],kind="bar",color=color,figsize=(4,3))
plt.show()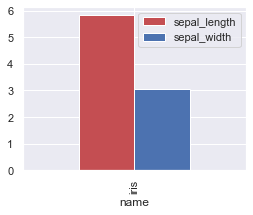
箱ひげ図を作成する
続いて箱ひげ図も作成してみましょう
from matplotlib import pyplot as plt
import seaborn as sns; sns.set()
#あらかじめ用意されているirisのデータを使用
iris = sns.load_dataset('iris')
sns.boxplot(x=iris["sepal_length"],y=iris["species"])
plt.show()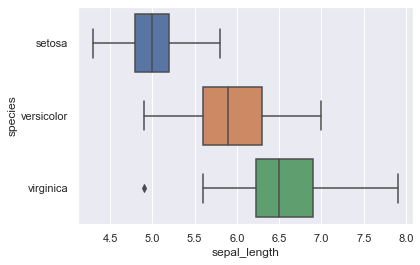
今回はseabornを使用して箱ひげ図を作成しています
seabornを使用すると勝手に綺麗な見た目のグラフになるので、おすすめです
seabornを学ぶなら以下の書籍がおすすめです

まとめ
- データの代表値には「計算的代表値」「位置的代表値」の2種類
- 平均値・中央値・四分位数をよく使う
- ノンパラデータは基本的に四分位数+箱ひげ図













