
これまでの記事で、twitterから情報収集する方法や形態素解析・wordcloudを行う方法を解説してきました
今回は、この両者を組み合わせて、人気のツイートを取得し、取得したツイートを一つのテキストファイルとして保存し、形態素解析・wordcloudを行う方法について解説していきたいと思います
自分の知りたいキーワードでは、どういったことがよくツイートされているのか?
そういった傾向を掴み、分析に活かすことができます
pythonでtwitterからツイートを取得したい
形態素解析・wordcloudを実施してみたい
取得したツイートを解析してみたい
といった方に向けて、書いていきます!
以下の記事では、pythonでtwitterを使う方法をまとめて解説しているので、参考にしてみてください
pythonでtwitterを扱えるようになると、twitterで行われている懸賞に自動で応募することができるようになります
コピペでOK!アフタフォロー付きのtwitter懸賞自動化コード
また、twitterアフィリエイトを自動化することもできます
コピペでOK!pythonを使ってtwitterアフィリエイトを自動化しよう
Contents
pythonでtwitterからツイートを取得して、形態素解析を行う

まずはコード全体を
import tweepy
from datetime import datetime,timezone
import pytz
import pandas as pd
import collections
import MeCab
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import seaborn as sns
sns.set(font='Hiragino Sans')
CONSUMER_KEY = ''
CONSUMER_SECRET = ''
ACCESS_TOKEN = ''
ACCESS_SECRET = ''
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_SECRET)
api = tweepy.API(auth)
search_results = api.search_tweets(q="", result_type="recent",tweet_mode='extended',count=5)
tw_data = []
for tweet in search_results:
#tweet_dataの配列に取得したい情報を入れていく
tw_data.append([
tweet.id,
tweet_time,
tweet.full_text,
tweet.favorite_count,
tweet.retweet_count,
tweet.user.id,
tweet.user.screen_name,
tweet.user.name,
tweet.user.description,
tweet.user.friends_count,
tweet.user.followers_count,
create_account_time,
tweet.user.following,
tweet.user.profile_image_url,
tweet.user.profile_background_image_url,
tweet.user.url
])
#取り出したデータをpandasのDataFrameに変換
#CSVファイルに出力するときの列の名前を定義
labels=[
'ツイートID',
'ツイート時刻',
'ツイート本文',
'いいね数',
'リツイート数',
'ID',
'ユーザー名',
'アカウント名',
'自己紹介文',
'フォロー数',
'フォロワー数',
'アカウント作成日時',
'自分のフォロー状況',
'アイコン画像URL',
'ヘッダー画像URL',
'WEBサイト'
]
#tw_dataのリストをpandasのDataFrameに変換
df = pd.DataFrame(tw_data,columns=labels)
df1=df.iat[2,2]
df2=df.iat[3,2]
tw_text=df1 + df2
f=open('text.txt','w')
f.write(tw_text)
f.close
f= open("/text.txt", 'r', encoding='UTF-8')
text=f.read()
f.close()
tagger =MeCab.Tagger()
tagger.parse('')
node = tagger.parseToNode(text)
word_list=[]
while node:
word_type = node.feature.split(',')[0]
if word_type in ["名詞",'代名詞']:
word_list.append(node.surface)
node=node.next
word_chain=' '.join(word_list)
c=collections.Counter(word_list)
font_path='/System/Library/Fonts/ヒラギノ明朝 ProN.ttc'
words = ['https','t','co','自民','し','w','そう', 'ない', 'いる', 'する', 'まま', 'よう', 'てる', 'なる', 'こと', 'もう', 'いい', 'ある', 'ゆく', 'れる', 'ん', 'の']
result = WordCloud(width=800, height=600, background_color='white',
font_path=font_path,regexp=r"[\w']+",
stopwords=words).generate(word_chain)
result.to_file("./wordcloud_sample1.png")
print(c.most_common(20))
fig = plt.subplots(figsize=(8, 10))
sns.set(font="Hiragino Maru Gothic Pro",context="talk",style="white")
sns.countplot(y=word_list,order=[i[0] for i in c.most_common(20)],palette="Blues_r")基本的にはこれまでに解説してきたコードをうまく組み合わせることで、可能になります
twitter APIの取得
pythonでtwitterを扱うには、twitter APIの取得が必要になります
twitter APIの取得は大きく分けると、3段階に分かれています
- Developerに登録
- twitter APIの使用用途を説明
- twitter APIの申請→承認
ざっくり上記の流れになります
twitter APIの申請は年々厳しくなっていますが、2022年に承認を受けた方法はこちら

tweepyのインストール
twitte APIの申請を終えたら、tweepyをインストールしていきます
pip install tweepyMacの場合には、ターミナルで上記コードを入力すればOKです
windowsの場合には、コマンドプロンプトで上記のコードを入力します
形態素解析を行う準備
形態素解析はMecabを使用していきます
pythonでMecabを使用するには、以下のようになります
- pythonの環境構築を行う
- Homebrewのインストール
- MeCabと形態素解析に必要な辞書をインストール
- MeCabの動作確認
- mecab-ipadic-NEologdのインストール
まだMecabの準備ができていない場合には、以下の記事を見つつ、準備を進めていきましょう

pythonでtwitterからツイート取得・形態素解析のコード解説
ここからはコードの解説をしていきたいと思います
twitter APIの認証
import tweepy
CONSUMER_KEY = ''
CONSUMER_SECRET = ''
ACCESS_TOKEN = ''
ACCESS_SECRET = ''
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_SECRET)
api = tweepy.API(auth)pythonでtwitterを扱う場合には、必ずといって良いほど、上記のコードを入力していきます
これはtwitter APIの認証です
まずはこれを記載しておかないと、pythonでtwittreを操作することができません
検索キーワードの設定
#tweepyで検索を行う
search_results = api.search_tweets(q="", result_type="recent",tweet_mode='extended',count=5)
「api.search_tweets」でqにキーワードを入力することで検索をすることができます
#例
#tweepyで検索を行う
search_results = api.search_tweets(q="大谷翔平", result_type="recent",tweet_mode='extended',count=5)
result_typeは3種類です
- “recent”:時系列で最新ツイートを検索
- “popular”:人気のあるツイートを検索
- “mixed”:上記を混ぜたもの
となっています
デフォルトでは、”recent”になっているので、変更する場合には、「result_type=””」で指定する必要があります
tweet_mode=’extended’では、ツイート内容の全文を取得するための記載です
count=5は取得するツイート件数を決めています
データフレームの作成
tw_data = []#tw_dataという空のリストを作成
#ここからツイート情報を取得
for tweet in search_results:
tw_data.append([
tweet.id,
tweet_time,
tweet.full_text,
tweet.favorite_count,
tweet.retweet_count,
tweet.user.id,
tweet.user.screen_name,
tweet.user.name,
tweet.user.description,
tweet.user.friends_count,
tweet.user.followers_count,
create_account_time,
tweet.user.following,
tweet.user.profile_image_url,
tweet.user.profile_background_image_url,
tweet.user.url
])
#取り出したデータをpandasのDataFrameに変換
#CSVファイルに出力するときの列の名前を定義
labels=[
'ツイートID',
'ツイート時刻',
'ツイート本文',
'いいね数',
'リツイート数',
'ID',
'ユーザー名',
'アカウント名',
'自己紹介文',
'フォロー数',
'フォロワー数',
'アカウント作成日時',
'自分のフォロー状況',
'アイコン画像URL',
'ヘッダー画像URL',
'WEBサイト'
]
#tw_dataのリストをpandasのDataFrameに変換
df = pd.DataFrame(tw_data,columns=labels)取得したツイートをデータフレームに変換します
その後テキストファイルに保存をしていきますが、その時に「ツイート本文」が含まれているセルだけをテキストファイルとしていきます
df1=df.iat[2,2]
df2=df.iat[3,2]
tw_text=df1 + df2
f=open('text.txt','w')
f.write(tw_text)
f.closeiatで指定をしていますが、ツイート本文全てを選択し、結合・テキストファイル保存をして起きます
保存したテキストファイルを読み込む
f= open("/text.txt", 'r', encoding='UTF-8')
text=f.read()
f.close()保存したテキストファイルをパス名で指定して、読み込みます
ここまできたら、あとは形態素解析・wordcloudを行うだけです
形態素解析・wordcloudを行う
tagger =MeCab.Tagger()
tagger.parse('')
node = tagger.parseToNode(text)
word_list=[]
while node:
word_type = node.feature.split(',')[0]
if word_type in ["名詞",'代名詞']:
word_list.append(node.surface)
node=node.next
word_chain=' '.join(word_list)
c=collections.Counter(word_list)
font_path='/System/Library/Fonts/ヒラギノ明朝 ProN.ttc'
words = ['https','t','co','自民','し','w','そう', 'ない', 'いる', 'する', 'まま', 'よう', 'てる', 'なる', 'こと', 'もう', 'いい', 'ある', 'ゆく', 'れる', 'ん', 'の']
result = WordCloud(width=800, height=600, background_color='white',
font_path=font_path,regexp=r"[\w']+",
stopwords=words).generate(word_chain)
result.to_file("./wordcloud_sample1.png")
print(c.most_common(20))
fig = plt.subplots(figsize=(8, 10))形態素解析を行い、その後にwordcloudを実行、画像として出力という流れになっています
wordcloudで抽出するのは、「名詞と代名詞」にしていますが、〇〇詞を変えることで、その他のものも抽出することができます
また、wordsでは除外するワードを指定しています
twitterのツイートではURLが貼られていることもあるので、それを除外します
出力結果はこちら

pythonを使って自分のツイートで「いいね」されやすい内容を分析

形態素解析ができるようになったら、もう少しツイッター分析に踏み込んでみましょう
ここからは、自分のツイートで「いいね」されやすい内容を分析していきたいと思います
過去のツイートデータを取得
過去のツイートデータはtwitter純正のTwitterアナリティクスから取得することができます
これは、PCからでしか取得することができないので、スマホで見ているからは、PCから開き直しましょう
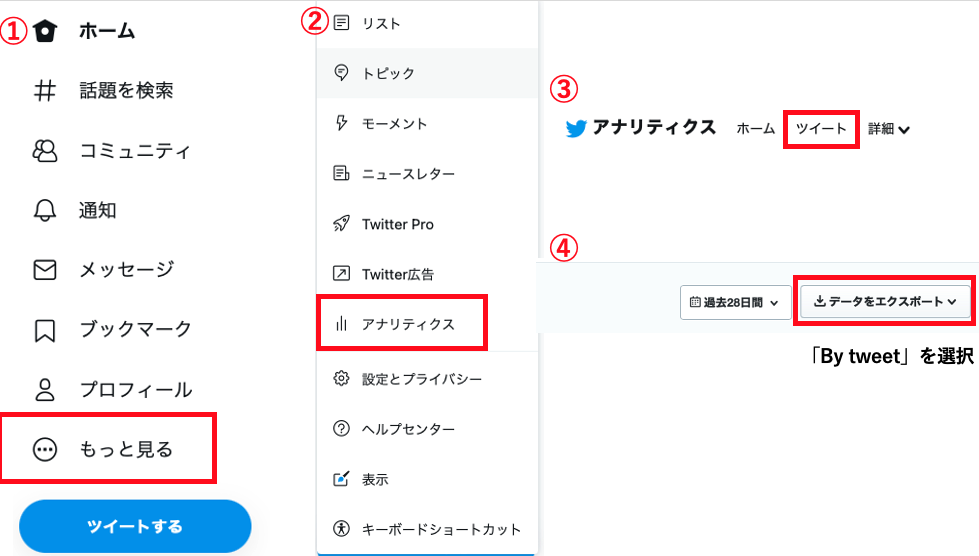
ツイートのいいねを分析する
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import japanize_matplotlib
#CSVの読み込み
apr_df=pd.read_csv("******.csv")
may_df=pd.read_csv("******.csv")
jun_df=pd.read_csv("******.csv")
#CSVを結合させる
combine=[apr_df,may_df,jun_df]
#データフレームを作成し、いいねが多い順に並べる
tweets_df=pd.concat(combine).sort_values(by="いいね",ascending=False)
#分析に必要なデータのみを取り出す
tweets_df=tweets_df[["ツイート本文","リツイート","時間","いいね"]]
#グラフを描写
tweets_df.plot.hist(y=["いいね"],bins=50,figsize=(16,9))
#グラフを保存
plt.savefig("ヒストグラム.png")
#時間データから日付や分数を取り除く
tweets_df["時間"]=pd.to_datetime(tweets_df["時間"])
tweets_df["時刻"]=tweets_df["時間"].dt.hour
#いいね数と時刻のデータフレームを作成
time_df = tweets_df[["いいね","時刻"]]
#時刻順に並び替える
time_df = time_df.sort_values(by=["時刻"],ascending=True)
#時刻ごとにデータを集計
grouped = time_df.groupby("時刻")
#時刻ごとの平均いいね数
mean = grouped.mean()
#時刻ごとのツイート数
size = grouped.size()
#時刻ごとの平均いいね数の棒グラフを描写
mean.plot.bar(xlim=[0,23], ylim=[0,90],figsize=(16,9))
#時刻ごとのツイート数の折れ線グラフを描写
size.plot(xlim=[0,23], ylim=[0,90],figsize=(16,9))
#描写したグラフを保存
plt.savefig("時刻別平均いいね数とツイート数.png")
#評価付け
tweets_df.loc[tweets_df["いいね"] >= 50, "いいね評価"] ="A"
tweets_df.loc[(tweets_df["いいね"] < 50) & (tweets_df["いいね"] >= 30), "いいね評価"] = "B"
tweets_df.loc[(tweets_df["いいね"] < 30) & (tweets_df["いいね"] >= 20), "いいね評価"] = "C"
tweets_df.loc[(tweets_df["いいね"] < 20) & (tweets_df["いいね"] >= 10), "いいね評価"] = "D"
tweets_df.loc[tweets_df["いいね"] < 10, "いいね評価"] = "E"
#各ツイートの文字数を取得
tweets_df["文字数"] = tweets_df.ツイート本文.str.len()
#評価用リストを作成
hyoka = ["A", "B", "C","D", "E"]
#評価ごとの平均文字数を格納するデータフレームを作成
fav_mean_df = pd.DataFrame(index = hyoka, columns = ["平均文字数"])
#作成したデータフレームに平均文字数を格納
for i in hyoka:
df = tweets_df[tweets_df.いいね評価 == i]
fav_mean_df.loc[[i],["平均文字数"]] = df["文字数"].mean()
#グラフを描写
fav_mean_df.plot.bar(figsize=(16,9))
#描写したグラフを保存
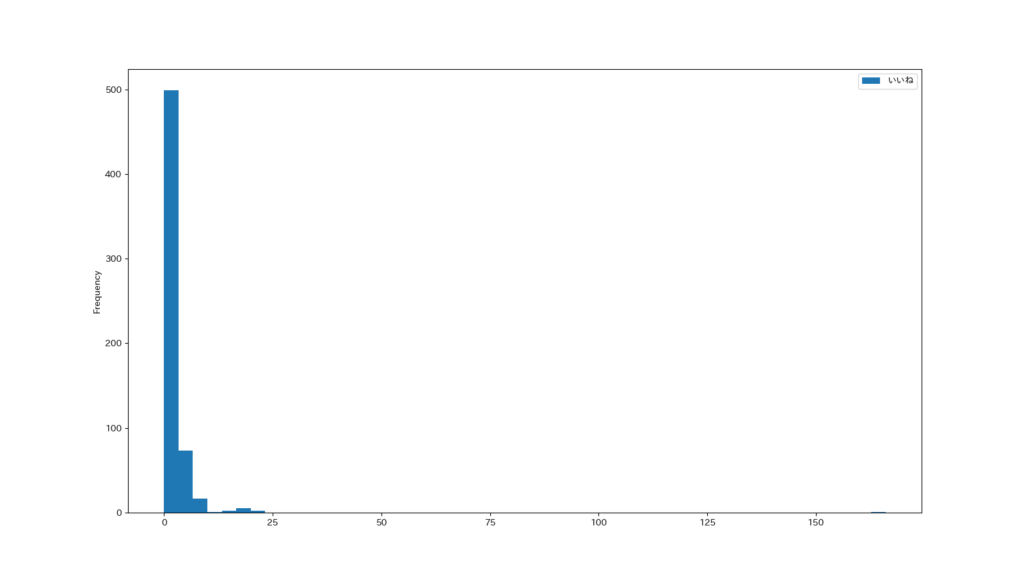
plt.savefig("いいね評価ごとの平均文字数.png")まずはどれくらいのツイート数、いいねをもらえているかを見てみます
僕のツイートのほとんどはいいねがもらえていないことがわかりますw
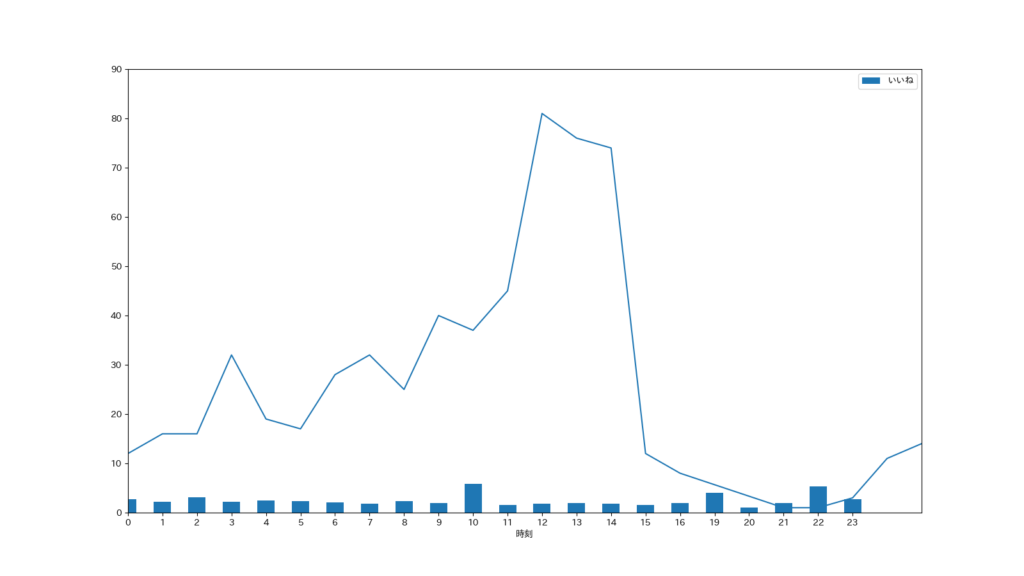
次にどの時間帯がいいねとツイートが多いのかを棒グラフと折れ線グラフで見ていきます
棒グラフがいいねの数、折れ線グラフがツイート数です
僕の場合は、11-14時くらいが一番多そうです(絶賛お仕事中のはず…)
いいねに関しては突出しているわけではありませんが、10時と19時、22時が多そうです
なので、この時間帯にツイートを連発すればいいねがたくさんもらえるかもしれません
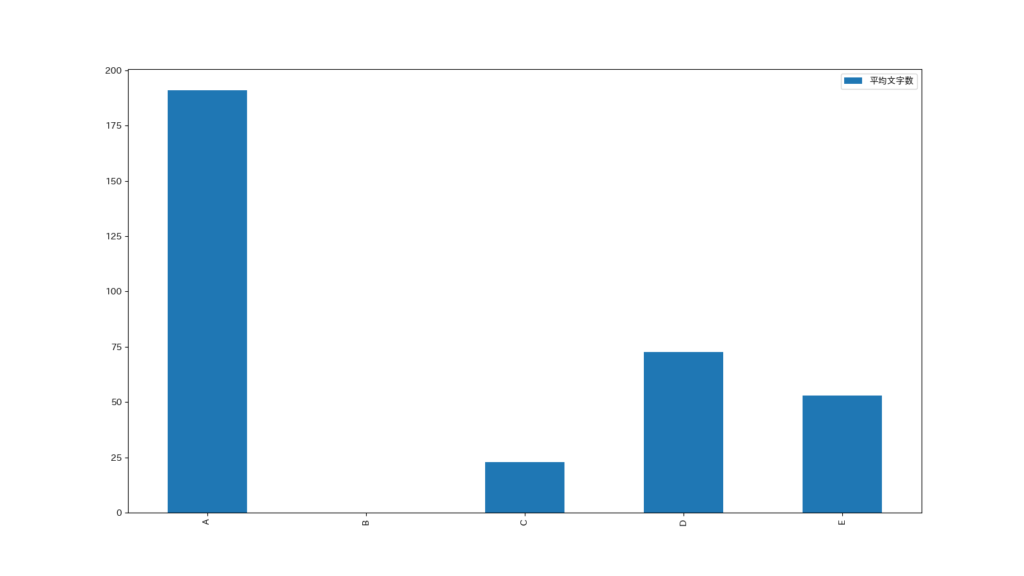
最後に、いいねをしてもらえるツイートの文字数です
イメージ的には文字数が多いほうが、いいねしてもらえそうですが、このグラフを見るとそうとも言えなそうですね
これをそのまんま多群比較の統計検定にかけたら違いがわかりそうです
ただまぁ、Bがない時点で、文字数はあまり関係なさそうですね
一通りの画像出力は上記のコードで分析可能です
コピペで動くように作っていますので、ぜひ自身のtwitter分析に活用してみてください
おすすめプログラミングスクール(無料体験あり)









