
Pythonはマーケティングに活用することもできるプログラミング言語です
マーケティングをしっかり学んだら、あとはPythonを学びながらデータ分析をしていけば、マーケティングに活用することができます
この記事では、Pythonを使ってマーケティングに活用することができるデータ分析手法を解説していきたいと思います
ぜひ読みながら実装してみてください
マーケティングスキルを身に付けたい方は、こちらから

本記事をお読みいただくことで、マーケティングに活用できるデータ分析手法がわかり、サンプルコードを使って、Pythonで実装することができます
筆者について
2021年から本格的にPython学習を始め、今ではPythonによる収益化に成功
大学院時代には、R言語とPythonを使って統計処理を行っていたため、Pythonを使ったデータサイエンスの知識が豊富
医療データを機械学習を用いて解析したり、学会発表も行なっている
Contents
Pythonでマーケティングに活用できるデータ分析手法

Pythonでマーケティングに活用できるデータ分析手法は、次の通りです
- 統計検定
- クラスター分析
- 決定木
- 勾配ブースティング木
- コレスポンデンス分析
- コンジョイント分析
- アップリフトモデリング
- デシル分析
- RFM分析
それぞれ1つずつ解説をしていきます
統計検定

統計検定は、仮説が統計的に正しいかを確認するための手法です
大量のデータを収集し、分析することで、そのデータからパターンや特徴を明らかにしていきます
また、2群以上で偶然によらない違いがあるよね?ということを明らかにするのも統計検定です
例えば、晴れの日にはアイスクリームの売り上げが高いけど、雨の日にはアイスクリームの売り上げが低い気がする
という仮説があった場合、晴れの日のアイスクリームの売り上げと雨の日の売り上げを比較し、偶然売り上げに差が生じたわけではないことを明らかにします

クラスター分析

クラスター分析も統計で実装することがあったりしますが、階層的と非階層的クラスター分析でもやや異なりますので、別にしています
クラスター分析は、機械学習の中でも教師なし学習に分類される、機械学習手法になります
マーケティングで実装する場合には、非階層的クラスター分析であり、k-means手法と呼ばれる手法が有名です
非階層的クラスター分析では、クラスター数を事前に決めておく必要がありますが、エルボー法などを使えば、恣意性を最小限にすることができるので、k-means手法とエルボー法は覚えておくことをおすすめします

scikit-learnのサンプルデータでクラスタリングを実装していきます
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
from sklearn.datasets import load_linnerud
linnerud = load_linnerud()
X=pd.DataFrame(linnerud.data,columns=linnerud.feature_names)
sc=StandardScaler()
clustering_sc = sc.fit_transform(X)
# K-means法によるクラスタリング
kmeans=KMeans(n_clusters=2,random_state=0)
results=kmeans.labels_
centers=kmeans.cluster_centers_
# クラスタリングの適用
cluster = kmeans.predict(X)
df_cluster=X.copy()
df_cluster['cluster']=cluster
sns.scatterplot(x="Situps",y="Jumps",hue="cluster",data=df_cluster)
plt.show()決定木

ディシジョンツリー分析とも呼ばれる決定木分析は、ある目標やゴールに向かう上で出てくる選択肢を選出し、それぞれを評価・比較するための分析手法です
特にマーケティング分野では、広告を新たに出すべきか?ダイレクトメールを送付するか?などの意思決定時に活用されることが多い分析手法です
Pythonを使うことで、Pythonでしか作ることができない決定木を作ることができます
>>>Pythonでしか描けない美しいディシジョンツリー(決定木)を描こう!
上記のサイトに記載されているサンプルコードをもとに、実装してみましたが、エラーが出てしまうので、一部修正したコードを掲載します
google colaboratoryを使って実装をしていきます
from google.colab import drive
drive.mount('/content/drive')!pip install japanize-matplotlib
!pip install statsmodels
!pip install graphviz
!pip install dtreeviz%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font="IPAexGothic")
from scipy.stats import norm
import sklearn
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
import statsmodels.api as sm
from sklearn.linear_model import LogisticRegression #ロジット回帰の場合、このライブラリが必要
from sklearn import tree
import dtreeviz
import graphviz
df_future = pd.read_csv('titanic_test_mod.csv')
df_past = pd.read_csv('titanic_train_mod.csv')
print(df_past.head())
#相関係数行列(ヒートマップ)説明変数間の相関係数が高すぎるものは注意
plt.figure(figsize=(9,7))
sns.heatmap(df_past.corr(), annot=True, vmax=1, vmin=-1, center=0)
plt.show()
#カラム=変数名を確認
print(df_past.columns)
#X_nameに説明変数を、y_nameに目的変数を設定
X_name = ['Pclass','Sex', 'Age', 'SibSp', 'Fare']
y_name = ['Survived']
X = df_past[X_name]
y = df_past['Survived']
model = sm.Logit(y,sm.add_constant(X))
result = model.fit()
print(result.summary())
print(result.predict(sm.add_constant(df_future[X_name])))
dtree = tree.DecisionTreeClassifier(max_depth=2)
dtree.fit(X,y)
# 決定木
viz = dtreeviz.model(dtree,X,y,
target_name = y_name,
feature_names = X_name,
#orientation='LR',
class_names = ["bad","soso","good"])
v=viz.view()
v.show()
v.save("test.svg")勾配ブースティング木分析

勾配ブースティング木分析も機械学習の一種で、決定木・勾配降下法・ブースティングを用いて予測モデルを構築する際に使用されます
3種類の分析手法を用いて解析を行なっていきますので、精度が高いというメリットがあります
Pythonで勾配ブースティング木分析を行っていく場合には、
- Xgboost
- LightGBM
- Catboost
などを使って分析を行っていきます
また、勾配ブースティング木分析は特徴量のスケールが違う場合でも、適切に扱うことができるなど、汎用性が高い手法として注目されています
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.ensemble import GradientBoostingClassifier
# サンプルデータセット(アイリスデータセット)の読み込み
data = load_iris()
X = data.data
y = data.target
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 勾配ブースティング木分析のモデルを定義
gb_clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
# 訓練データを使ってモデルを訓練
gb_clf.fit(X_train, y_train)
# PCAでデータを2次元に縮約
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# 2次元に縮約されたデータで勾配ブースティング木分析を実行
X_train_pca, X_test_pca, y_train_pca, y_test_pca = train_test_split(X_pca, y, test_size=0.3, random_state=42)
gb_clf_pca = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
gb_clf_pca.fit(X_train_pca, y_train_pca)
# 境界線をプロットする関数を定義
def plot_decision_boundary(clf, X, y, ax, title):
h = .02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, alpha=0.8)
scatter = ax.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o', s=50)
ax.set_title(title)
legend1 = ax.legend(*scatter.legend_elements(),
loc="lower right", title="Classes")
ax.add_artist(legend1)
# 可視化
fig, ax = plt.subplots(figsize=(8, 6))
plot_decision_boundary(gb_clf_pca, X_pca, y, ax, "Gradient Boosting (2D PCA)")
# グラフを表示
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.show()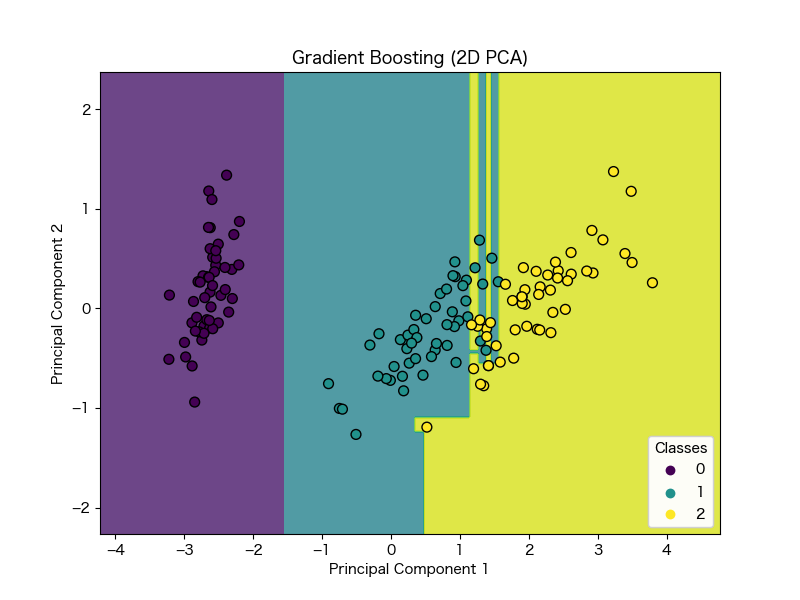
注意点として、アイリスのデータは4次元ですが、可視化には2次元にする必要があるため、次元削減処理を行なっています
そのため、本来のデータの一部が失われている可能性も考慮しておく必要があります
コレスポンデンス分析

コレスポンデンス分析は、2つ以上の質的変数の間の関係を可視化するための多変量解析手法です
例えば、商品の種類や地域、年齢層など、カテゴリーに分けられる変数同士の関係を分析する場合に用いられます
また、コレスポンデンス分析は、主成分分析と同様に、データの次元削減が可能な手法で、2次元平面上に多数の変数を表現するため、分析結果を直感的に理解することができる点が特徴的です
市場調査やマーケティング分析などの分野で、消費者の購買行動や嗜好の分析に用いられることが多く、カテゴリー変数の解析において、有用な手法です
コンジョイント分析

コンジョイント分析は、製品やサービスの評価方法の一つで、製品やサービスの構成要素や属性について、どのような価値観を持つ顧客がいるかを分析するための手法です
顧客が製品やサービスのどの属性や要素を重視しているかを明らかにし、それに基づいて製品やサービスの最適化を図ることができます
たとえば、価格が重視される場合は価格を下げたり、機能性が重視される場合は機能を強化したりすることで、顧客のニーズに合った製品やサービスを提供することができます
また、既存の製品やサービスだけでなく、新規製品やサービスの開発にも有用です。
顧客が求める属性や要素を分析することで、新しい製品やサービスのコンセプトを明確化したり、開発段階での改善点を把握することができ、マーケティングにおいて重要な分析手法となります
アップリフトモデリング

アップリフトモデリングとは、マーケティング施策の効果測定手法の一つで、顧客を施策を行うグループと非行うグループにランダムに分け、その2つのグループの間で施策による効果の差分(アップリフト)を分析することで、施策の効果を評価する手法です
具体的には、ある施策を行ったグループと行わなかったグループにおいて、それぞれのグループに含まれる顧客の購買行動を観測し、施策による差分を算出します
その際に、ランダムな割り振りを行うことで、施策の影響以外の要因を均一化することができます
例えば、あるオンラインショップでは、商品購入に至るまでの流れについてアップリフトモデリングを実施しました
その結果、商品を購入するまでに、サイト上での閲覧回数が増加した場合、実際に購入する確率が高まることが分かりました
この知見をもとに、サイト上での閲覧回数を増やす施策を展開し、売上を増加させることに成功したという事例があります
アップリフトモデリングは、マーケティング戦略の最適化に役立つ分析手法です
Pythonでは、scikit-learnを使うことで、アップリフトモデリングを実装することができます
デシル分析

デシル分析とは、データを同数のグループに分け、各グループの平均値を比較する方法です
一般的には、全体の10分の1ごとに分けることが多いため、「10分位数分析」とも呼ばれます
デシル分析は、ビジネスやマーケティング分野で顧客や製品の分析に使用されます
例えば、売上高や利益などの指標に基づいて、顧客や商品をランキングして比較することができます
Pythonでデシル分析を行うには、pandasやseaborn、matplotlibを使って可視化を行います
RFM分析

RFM分析とは、リピート率や購買金額に着目し、顧客の価値を定量的に評価する手法の一つです
RFMとは、下記の指標の頭文字をとったものです
- Recency(直近性):最近の購入日から顧客がどのくらい時間が経過しているか
- Frequency(頻度):顧客の購買回数
- Monetary(金額):顧客の購買金額
これらの指標を用いて、顧客を分析し、顧客の価値を高い順にランク付けすることができます
高いランクの顧客には、優遇措置や特別なサービスを提供することで、顧客ロイヤルティの向上や顧客の生涯価値の増加を狙うことができます
RFM分析は、データ分析やマーケティングにおいて広く利用されており、Pythonでも実装することができます
Pythonでデータ分析を学ぶ方法

Pythonはデータ分析に関するライブラリが豊富に用意されており、初心者でも手軽にデータ分析を行うことができます
ここからは、Pythonでデータ分析を学ぶ方法について解説をしていきます
独学でデータ分析を学ぶ

独学でデータ分析を学ぶ場合には、書籍を利用するのがおすすめです
Python2年生 データ分析のしくみ 体験してわかる!会話でまなべる!

python1年生で学んだ方もいるかもしれませんが、python2年生ではデータ分析を学ぶことができます
このシリーズはイラストも多く、データ分析をイメージしながら学習しやすいのが特徴です
統計学に入る前、データ分析に必要な前処理やデータ自体の見方、可視化の方法などを学ぶことができます

Pythonで学ぶあたらしい統計学の教科書 第2版

pythonで統計学を独学で学ぶのに、最も使用した本です
この本では、統計学のみならず、機械学習について学ぶことができるため、これからデータサイエンティストを目指している方におすすめの本です
pythonで統計学をどのように処理していくのかはもちろんわかりますが、そもそもの統計学の知識も学ぶことができる一石二鳥な本となっています
もしこれから先、pythonを使ったデータサイエンティストになりたいと考えているのであれば、必ず目を通しておきたい本です

Python実践データ分析100本ノック 第2版

pythonで統計学を学びつつ、実際にデータ分析を行なっていくことで、実践力・応用力が身についていきます
「Python実践データ分析100本ノック 第2版」では、現場で遭遇する汚いデータをどのように扱っていくかを学ぶことができます
データ分析をしたことがある方ならわかるかもしれませんが、分析に使用するデータは単位が揃っていなかったり、空欄があったりします
そういった時にどのように対応するのかがこの本で学ぶことができます

プログラミングスクールを利用する

データ分析をプログラミングスクールで学ぶなら、データミックスがおすすめです
datamixを受講すると、データ分析の基礎から応用までを学習でき、身に付けたスキルはビジネスシーンで活用することができます
高額な受講費に関しては、教育訓練給付金制度が利用でき最大約51万円もの金額が返金されるので、他のプログラミングスクールよりも低価格でハイクオリティな講義を受けることができます
これから先の時代、データ分析を学んでいる人材は重宝されます
現に、アメリカでは年収が1500万を超える人もいます
国内においても、徐々にデータ分析ができる人の需要が高まってきていますので、将来性も非常に高い分野です
ぜひ、datamixでデータ分析を身につけてくださいね
※無料オンライン相談や個別相談などさまざまなイベントが開催中








