
また、ヒストグラムの作図や代表値などについても触れてきました
今回の記事では、論文投稿の際に求められることが増えてきていると言われている「 95%信頼区間」をpythonで求めていきたいと思います
Rを使用すれば、t値とp値の他にも信頼区間が算出されますが、pythonでは別にコードを入力しないと、95%信頼区間は算出できません
ウェルチのt検定をRとPythonでやってみる
Pythonではt値とp値だけ出力。なので、95%信頼区間が欲しければ別にコードを打たないといけない。
Rではt値とp値だけでなく、平均値差の95%信頼区間も含めて色々出力されます。
良し悪しではなく、特徴の違いです。
こういう統計関連はRが強い。 https://t.co/bYu6LMXXS4 pic.twitter.com/5Os00zV3sE— さくら🌸医療統計・データサイエンス (@Sakura_Med_DSci) October 19, 2021
pythonで95%信頼区間を算出する場合には、
stats.norm.interval()を使用する
Contents
95%信頼区間とは
95%信頼区間とは、
「母集団から標本を取ってきて、その平均から95%信頼区間を求める、という作業を100回やったときに、95回はその区間の中に母平均が含まれる」
ということを示しています
信頼区間は区間推定、平均値などの代表値を使用したものは点推定と呼ばれています
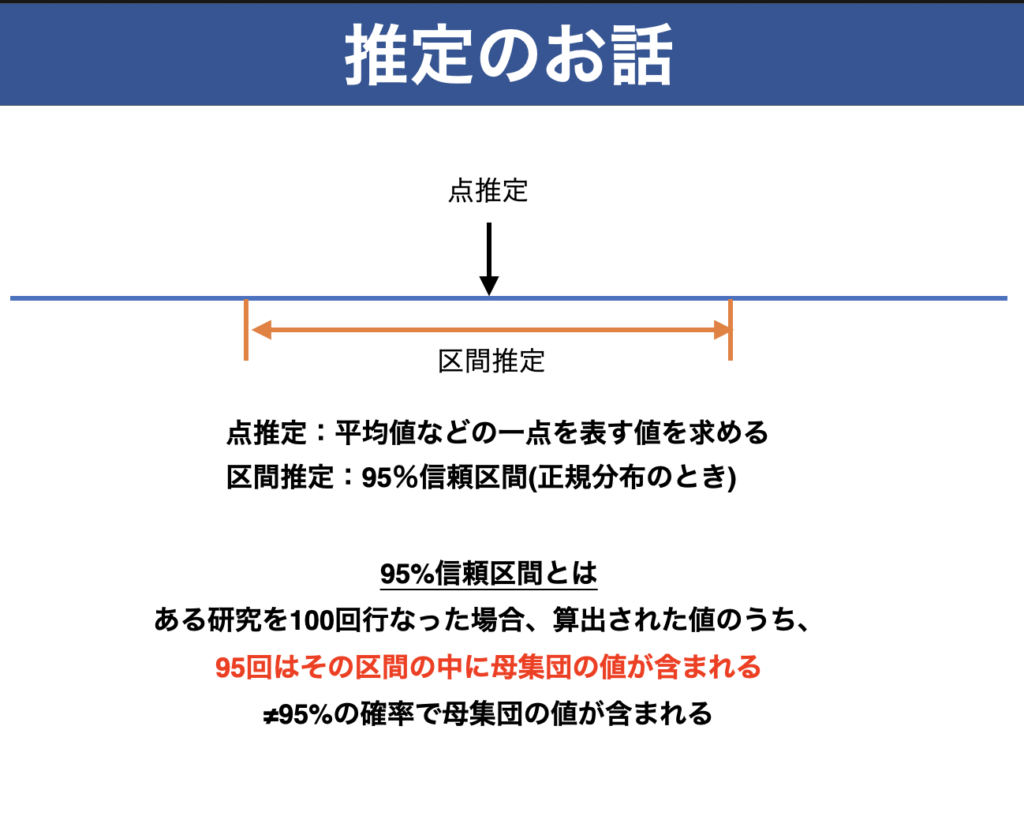
信頼区間の求め方
信頼区間はRやpythonを使用しなくても算出することができます

しかし、標本平均を求めたり普遍分散を求めたりと、作業が大変になります
pythonやRを使用すれば、簡単に算出することが可能です
pythonで95%信頼区間を算出する
では、ここからは実際にpythonを操作しながら、95%信頼区間を算出していきたいと思います
ライブラリのインポート
まずは95%信頼区間を算出し、グラフ化するために必要なライブラリをインポートしていきます
import pandas as pd
import seaborn as sns
sns.set()今回は無料配布されているirisのデータをpandasからインポートして使用していきますので、そちらも合わせてインポートしておきましょう
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
sepal_length=iris.iloc[:,0]
print(sepal_length)今回はirisデータのsepal_lengthを使用していきたいと思います
分布の確認
ひとまず分布の確認をしておきます
import pandas as pd
import seaborn as sns
sns.set()
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
sepal_length=iris.iloc[:,0]
print(sepal_length)
sns.displot(sepal_length)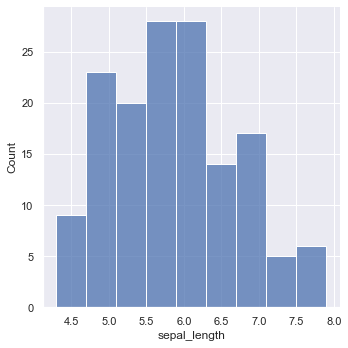
正規分布かどうかが視覚的にわからない場合には、正規性の検定を用います

信頼区間を算出する場合、平均値を用いるため基本的には正規分布でしか使用しないと考えています
母平均を算出する
今回は上記のsepal_length150件を母集団としておき、母集団の平均である母平均を算出します
(※本来であれば、母集団はわかりません。それを推定するのが区間推定になります)
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
sepal_length=iris.iloc[:,0]
print(sepal_length.mean())
#結果5.84母集団の平均は「5.84」であることがわかりました
標本の作成
では、ここからはsepal_lengthからランダムで50件抽出した標本で話を進めていきたいと思います
import pandas as pd
import seaborn as sns
sns.set()
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
sepal_length=iris.iloc[:,0]
print(sepal_length.mean())
n=50
sample_df = sepal_length.sample(n=n)
print(sample_df.mean()).sample(n)を使用すれば、n件のデータをランダムで選択することができます
ランダムで50件抽出したら標本平均も算出します
母集団の平均は5.84
標本の平均は5.77
ということがわかります
95%信頼区間を算出する
では95%信頼区間を算出していきたいと思います
import numpy as np
from scipy import stats
import pandas as pd
import seaborn as sns
sns.set()
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
sepal_length=iris.iloc[:,0]
n=50
sample_df = sepal_length.sample(n=n)
sample_mean = np.mean(sepal_length)
sample_var = stats.tvar(sepal_length)
print(stats.norm.interval(alpha=0.95, loc=sample_mean, scale=np.sqrt(sample_var/n)))
結果は「(5.613809330617545, 6.0728573360491245)」になるかと思います
このことから95%の確からしさで母平均は5.61〜6.07の間に含まれる、ということになります
実際の母平均は「5.84」なので、この信頼区間は正しいといってもよさそうです
まとめ
- 信頼区間とは母集団から標本を取ってきて、その平均から95%信頼区間を求める、という作業を100回やったときに、95回はその区間の中に母平均が含まれる
- pythonではstats.norm.interval()で算出できる
- 母集団の平均は未知である
pythonで統計学を学ぶ上で必須書籍





スクールに通わずにpythonを学習するためには?
Python学習を進めていく上で、
「ひとまず何かしらの書籍に目を通したい」
「webで調べても全くわからない」
という状況が何度も何度でも出てくるかと思います。
そういう時に便利なのが、kindleとテラテイルです。
Kindleはご存知の通り、電子書籍です。
Kindleには多くのpython学習本が用意されており、無料で読むことができます。(たまに有料もあります)
ひとまずどういった書籍があるのか?
もしものために、書籍に目を通しておこう
という場合には、kindleの利用がおすすめです。








